Compiler - Semantic Analysis
이번 포스트에서는 컴파일러의 3번째 단계인 Semantic Analysis에 대해 다룬다.
Semantic Analysis
Semantic Analysis란?
Semantic vs Syntax
-
Semantic (의미) : 프로그램의 실제 의미를 정의함.
-
Syntax (구문): 프로그램의 형식적인 구조를 정의함.
Semantic Analysis(의미 분석기)
- 의미 분석의 역할 : Context-sensitive rules (문맥 민감 규칙)을 검증한다.
- CFG만으로는 잡아낼 수 없는 오류들을 체크
- ex)
y = x;-> x가 변수, 함수, 선언된 적이 있는지, 타입 맞는지를 체크할 필요가 있다.
- 구문 분석은 구조만 확인한다면, 의미 분석기를 통해 의미적으로 말이 되는지 확인할 수 있다.
- 두 가지 규칙 유형
- Context-free rules : 구조만 확인 (파싱에서 사용)
- Context-sensitive rules : scope, type 등 외부 정부가 필요 -> 이는 CFG에서만은 불가능하다.
=> 따라서 문법만으로는 논리적 오류를 잡을 수 없기 때문에 Semantic Analysis에서 의미 분석을 반드시 해야한다.
Context-Sensitive Rules
-
Semantic Analysis 는 Context-Sensitive Rules 를 뛴다.
-
다음은 Context-Sensitive Rules 들이다.
Rule 1 : 모든 변수는 사용 전에 선언되어야 한다.
-
예시 )
void foo() { x = 3; // 선언 안 된 x 사용 int x; }
Rule 2 : 동일한 scope 안에서 변수는 한 번만 선언 가능하다.
- 같은 Block 내에서 같은 이름의 변수는 한 번만 선언이 가능하다.
- 다른 Block에서는 같은 이름을 쓰는 것은 가능하다.
Rule 3 : 함수는 전역에서 한 번만 선언되어야 한다. (Overloading은 제외)
-
예시 )
void foo() {...} void foo() {...} // 중복된 함수 선언이다. -
C++ 과 같이 함수 오버로딩을 허용하는 경우는 예외적으로 허용한다.
Rule 4 : 변수는 선언된 타입에 맞게 사용해야 한다.
- 변수는 선언된 타입에 맞는 값으로만 초기화 / 사용되어야한다.
Rule 5 : 함수는 인자의 개수와 타입이 정확해야 한다.
-
예시
void foo(int a) { ... } foo(123); // foo(1, 2); // 인자 개수 불일치 -
Semantic Analysis는 함수 호출 시 인자의 수와 타입을 검사한다.
Scope Checking
Scope
- 변수나 함수의 선언이 유효한 영역을 의미한다.
- 어떤 선언이 보이는 (Visible)한 영역
- 보통 Block 단위의 새로운 Scope가 형성된다.
- Block : 변수 선언이 가능한 코드 단위 (전체, 함수, 중괄호 내부 등)
Scope Rules
- 동일한 블록 안에서 중복된 선언은 금지한다.
- 함수 선언의 scope : 선언된 지점부터 파일 끝까지 유효
- Built-in-function : 프로그램 전체에서 사용 가능하다.
- Ex) printf, putInt 등
- 블록 내 변수 Scope
- 변수는 선언된 지점부터 블록 끝까지 유효
- 중간에 선언에도 그 이후 코드에서만 수행 가능
- 함수 매개변수의 Scope
- 함수 본문 전체에서만 유효 (함수 헤더에서 선언된다)
Nesed Scope Rule : 동일한 이름의 식별자가 여러 Scope에 선언된 경우
- 가장 가까운 (innermost)한 선언을 사용한다.
- 검색 순서 : 현재 블록 -> 상위 블록 -> 전역
- Scope Hole : 내부 Scope에서 동일 이름으로 다시 선언되면 외부 선언은 가려진다.
- 외부 변수는 내부에서 보이지 않음.
=> Scope Level의 도입
Scope Level
각 선언에 대해 Scope Level 정보를 부여하여 구별로
AST에서 Block을 읽을 때마다 Level을 1씩 증가시킨다. 그 이후 선언이 있는 것들은 Symbol Table에 저장한다.
저장 방식
Name / Token / Scope Level
- 전역 : level 0
- 함수 내 : level 1
- 중첩 블록 : level 2,3,4,…
- 이러한 레벨 정보는 Symbol Table에 저장
Flat Symbol Table의 한계
- Flat Symbol Table : 각 항목마다 “이름” / “타입” / “Scope 레벨” 만 저장
- 같은 Scope Level 내의 다른 Block을 구분할 수가 없다. 중첩된 블록끼리 이름은 같지만 문맥이 다르다.
- 느린 탐색 기능으로 참조 확인 시에 전체 테이블을 뒤져야 한다.
- 효율성이 떨어진다. (항상 순회하며 가까운 선언을 찾아야 하기 때문)
즉, Flat Symbol Table 로는 Level만으로 정확한 블록을 구분하기 어렵다.
Nested Symbol Table
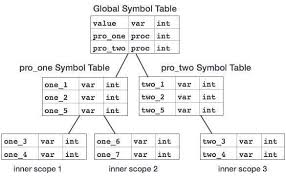
- 해결책 : Nested Symbol Table
- 각 Scope 마다 독립된 Symbol Table을 생성한다.
-
테이블 간의 부모 - 자식구조로 연결하여 선언된 위치에 따라 정확한 Scope 분리가 가능
- 구현 흐름
- AST를 탐색하면서 블록 진입시에 새 테이블을 생성
- 식별자 선언 시 현재 테이블에 추가
- 블록 종료 시 상위 테이블로 복귀
- 변수 참조 시에 동작 순서
- 현재 Scope에서 식별자 찾기
- 없으면 부모 테이블로 이동
- 계속 올라가다가 못 찾게되면 에러 처리
Two-Pass Scope Checking
- 함수나 구조체가 사용보다 나중에 정의되는 경우를 허용하기 위할 때 해결 방법
- 1차 패스 : 선언만 수집한다.
- (Symbol Table) 구축
- 2차 패스 : 사용 참조 처리 및 유효성 검사
Type Checking
Type Checking
- 프로그램 내의 값들이 의미 있는 방식으로 사용되고 있는지 확인하는 과정이다.
- 예) 정수끼리 더하는 건 가능 / 정수에 문자열을 더하려는 건 오류
-
컴파일 타임에 오류를 잡는 것이 Type Checking의 역할
- 프로그램이 실행되기 전에 타입 관련 오류를 조기에 탐지해준다.
- 안전성과 정확성의 증가
- Scope Checking 이후에 Type Checking을 진행해야 한다.
Type Checking의 절차
- 할당 문장이 문법적으로 맞는지 (타입 기준)
- 좌변과 우변의 타입이 같아야 한다.
- 연산 자체가 타입적으로 유효한지 확인
- 자유 변수가 실제로 선언되어 있고, 그 타입이 맞는지 확인
Static vs Dynamic Type Checking
| 항목 | Static | Dynamic |
|---|---|---|
| 검사 시점 | 컴파일 타임 | 실행 시간 |
| 예 | Java, C | Python, JavaScript |
| 장점 | 성능, 조기 오류 발견 | 유연성 |
| 단점 | 유연성 부족 | 오류 발견이 늦음 |
Rule of Inference
-
추론 규칙은 어떤 명제가 참이라는 것을 논리적으로 도출하기 위한 형식적인 규칙
-
컴파일러가 표현식의 타입이 유효한지 판단할 때 이러한 추론 규칙을 사용함.
-
수식 \(\frac{\text{조건 (Hypothesis)... 조건(Hypothesis)}}{\text{결론 (conclusion)}} \quad \text{(이름)}\)
-
⊢ x : τ→ x는 타입 τ를 가진다. -
S ⊢ e : τ→ S 에서 식 e는 타입 τ를 가진다.
핵심 표기법
S ⊢ s : Stmt
- S: 스코프 또는 타입 환경 (변수들의 타입 정보)
- s: 프로그램 문장(statement)
- ⊢: “증명할 수 있다”, “타입이 유도된다”
- 결론: “타입 환경 S 아래에서 문장 s는 잘 형성된 문장이다(valid Stmt)”
전제 : Type Checking 은 AST 위에서 이루어진다.
- AST는 코드의 구조와 연산 관계를 계층적으로 표현한 트리이다.
-
각 노드는 연산자, 변수, 대입문, 조건문 등을 나타낸다.
- DFS로 AST를 순회하여 Type Checking 하는 과정
- root부터 시작해서 재귀적으로 하위 노드를 탐색
- 각 노드에서 적절한 추론 규칙을 적용하여 타입을 유도
- 형식이 잘못된 노드가 있으면 즉시 에러 리포트