컴퓨터 통신 01.기본 개념
이번 포스트에서는 컴퓨터 통신의 기본 개념을 다룬다. 크게 목차는 아래와 같다.
- 컴퓨터 통신 - 왜 배워야하는가?
- 요구 사항
- 네트워크 구조
- 성능
컴퓨터 통신
정의 : “컴퓨터 기반 기기 간의 의미(정보) 교환”
- 주체는 기기 자체가 아니라 그 위에서 실행되는 응용 (앱)
- 응용 프로그램 간의 데이터 교환을 가능하게 하는 기술
- 사람 간의 대화와 유사하지만, 디지털 형태의 정보 교환이라는 점이 다르다.
4단계 과제
- 컴퓨터에서 의미란?
- 모든 의미는 데이터로 표현된다.
- 문자, 음성의 디지털화
- 통신에서 교환이란?
- 신호 송수신 과정으로 표현
- 0과 1 을 전기 / 무선 신호로 표현
- 즉, 의미 교환이란 디지털 데이터의 교환
- 직접 교환의 한계
- 기기끼리 직접 신호를 주고받을 수 있을까?
- 거리와 규모의 한계가 존재
- 스위칭 (Switching) 이라는 개념이 필요
- 서로 다른 통신망의 다양성
- 통신하는 양쪽의 통신망이 서로 다를 가능성이 존재함.
- 기술적 이질성을 극복
- 인터넷 (Internet) 출현
결론
컴퓨터 통신이란 컴퓨터 기반 기기/응용들이, 필요에 따라서 중계기/스위치를 경유하면서, 디지털 데이터를 담고 있는 신호를 교환해서, 의미를 교환하는 것을 말한다.
왜 공부해야하는가?
- 현대의 거의 모든 서비스는 데이터 통신 위에서 동작
- 클라우드, IoT, 메신저, 스트리밍, 원격 제어 등
- 신호, 하드웨어 수준까지는 깊게는 아니더라도 기술의 원리와 한계를 이해해야 응용 설계나 AI 서비스 구현에도 응용이 가능하다.
요구 사항 (Requirements)
요구 사항 1 : 연결 (Connectivity)
통신의 제 1업무 : 연결
-
통신 주체(terminal) : 실제로 데이터를 주고받는 쪽, 요즘은 “기기”보다 그 위의 응용 (카톡, 브라우저 등)이 주체라고 보는게 정확하다.
위 개념에서는 단말기로 가정
-
연결 방법 : 유선/무선 모두 가능하다.
-
통신망의 물리 구성요소
-
노드 (nodes) : 단말기, 워크스테이션, 라우터와 스위치 같은 중간장비 포함(= 처리, 중계 역할까지 포괄)
단말기도 node 에 포함된다.
-
링크 (links) : 동축/광케이블, 무선 채널 등 “신호가 지나가는 길”
-
연결 : 직접 링크 (Direct Links)
1. 점대점 연결 (point-to-point)
- 두 노드를 전용 링크로 바로 잇는 구조
- 장점 : 단순하고 간섭과 경합의 거의 없다. (둘만 쓰기 때문)
- 단점 : 노드 수가 늘면 링크 수가 급증
- 완전연결이면 링크 개수는 = N * (N - 1) / 2
- 규모가 커질수록 비현실적
2. 다중 접근 (multiple access)
- 여러 노드가 하나의 공유 링크를 함께 사용 (LAN의 기본 원리)
- 장점 : 케이블/무선 채널 하나로 다수 연결, 배선과 비용 확장성에 유리
- 단점 : 동시에 보내면 충돌이 발생하여 매채접근제어(MAC)이 필요
- 유선 이더넷의 CSMA/CD
- Wi-Fi의 CSMA/CA 같은 규칙
연결 : 간접 연결
Switched Networking : 스위치/라우터를 통한 연결
- 배경
- 거리가 멀면 직접 신호가 너무 어렵다. (감쇄, 중계가 필요)
- 규모가 커지면 P2P는 링크 수가 폭증
- 해법 : 중간 노드 (스위치/라우터)가 경로를 선택해 중계 (스위칭)
- 간접 연결으로 확장성을 확보
3. 스위칭 네트워크 (switching network)
- 하나의 “망” 안에서 스위치들이 연결 경로를 정함.
- 패킷 교환이 일반적
- store-and-forward, 주소/라우팅이 필요
4. 인터네트워킹 (Internetworks)
- 망과 망을 잇는 ‘망들의 네트워크’
- 이질적 기술/정책을 라우터가 연결 = (오늘날의 Internet의 본질)
스위칭 정책 : 어드레싱 및 라우팅
어떻게 연결을 유지하고 식별할 것인가?
회선 스위칭 (Circuit Switching)
- 전화망 방식의 스위칭
- 연결을 미리 확보하고 전용 회선 (circuit)을 통해 데이터(비트스트림)을 연속적으로 전송
- 즉 스위치가 사전에 output link를 전용으로 할당해 둔다.
- 한 번 연결되면 끊김 없이 송수신 (flow 유지) 가능
-
기본적으로 point-to-point 연결 구조
- 특징
- 연결 설정(setup) 과정이 반드시 필요
- 전용 회선이기 때문에 빈 시간에도 자원은 점유
- 효율이 떨어지지만 지연이 일정 (예측 가능)
- 음성 통화처럼 연속적인 데이터 스트림에 적합
- 문제점 : 컴퓨터 트래픽은 Bursty
- 잠깐 집중적으로 보내고, 한동안 아무것도 안 보낸다면 자원 낭비가 심함.
- 전화형 회선 스위칭은 데이터 통신에는 비효율적
패킷 스위칭 (Packet Swithcing)
- 인터넷의 기본 구조
- 회선처럼 미리 링크를 확보하지 않고, 데이터를 작은 조각(패킷)으로 잘라서 전송
- 각 패킷은 독립적으로 네트워크를 거치며 store-and-forward 방식으로 전달된다.
- 스위치는 패킷을 저장 후 다음 경로로 전송한다.
- 장점
- 네트워크 자원을 동적으로 공유하기에 효율성이 좋다.
- 트래픽이 bursty 해도 유휴 자원을 다른 사용자에게 할당이 가능하다.
- 장애가 발생 시에 경로가 우회 가능하다. (유연성)
- 문제점
- 패킷 단위의 저장과 전달이기에 지연이 변동된다.
- 순서가 뒤바뀔 수 있기 때문에 재조립이 필요하다.
어드레싱 (Addressing) 및 라우팅 (Routing)
연결의 선결 과제
- 통신의 목적지를 식별하기 위한 ID를 부여하는 과정
- 누구한테 보낼지를 정한다.
- 주소 (address) : 노드를 구별하는 고유한 바이트열 (IP, MAC 주소)
- 주소의 종류로는 유니캐스트 (1:1),브로드캐스트 (1:All), 멀티캐스트 (1:N)이 있음.
- 라우팅 (Routing) : 어떤 경로로 보낼지 결정하는 과정, 주소와는 다르게 동적 판단하는 로직이 포함
요구 사항 2 : 자원 공유 (Resource Sharing)
핵심 개념
- 현실의 네트워크 자원(노드,링크)은 한정되어 있다.
- 따라서 여러 사용자가 같은 통신 경로(link)를 효율적으로 공유해야 한다.
- 이를 위한 기술이 다중화 (Multiplexing, MUX)
- Switch 1 : MUX 역할로 데이터를 한 줄로 병합
- Switch 2 : DEMUX 역할로 다시 분리

여러 사용자의 데이터 -> 하나의 통로로 묶어서 보내고 (MUX)
다시 목적지에서 나눠주는 (DEMUX) 구조
- 이때 선택적으로 분리하기 위한 key/select 정보가 필요하다.
- 어떤 데이터가 누구의 것인지 구분하기
- 링크는 물리적, 논리적 둘 다 가능하다.
주파수분할 다중화 (Frequency Division Multiplexing)
개념
-
각 사용자가 서로 다른 주파수 대역을 사용
- 즉 한 링크 (케이블, 전파) 안에 여러 주파수 채널을 나누어 쓴다.
- 아날로그 기반 시스템에서 주로 사용
특징
- 동시에 전송이 가능
- 하지만 인접 주파수 간섭 방지를 위해서 guard band (보호대역) 이 필요함.
- 효율이 낮아진다.
연속적인 (analog) 신호가 필요할 때 유리함.
시분할 다중화 (Time Division Multiplexing)
개념
- 시간 (time)을 일정 구간으로 나눠서 사용자별로 번갈아가며 전송하는 방식
- 모든 사용자가 순서를 배정받고 차례로 데이터를 보낸다.
- 시간을 나눠쓴다의 개념
- 동기식 (Synchronous) TDM
- 각 사용자에게 고정된 시간 슬롯 (slot)을 할당
- 사용자가 전송할 데이터가 없어도 자신의 슬롯은 비워두고 지나간다.
- 약간의 낭비가 존재
- 하지만 FDM보다는 효율은 좋고 단순하다.
FDM 보다는 효율이 좋음.
통계적 다중화 (Statistical Multiplexing)
- 시분할 다중화의 발전형
- 고정된 시간 배분이 아니라, 요청이 있는 사용자에게만 시간 슬롯을 동적으로 할당
- 비동기식 TDM, On-demand TDM 이라고도 부름
동작 방식
- 송신 측 MUX가 각 사용자에게 데이터를 큐에 저장
- 전송할 데이터가 있는 사용자에게만 슬롯을 동적으로 배분
- 각 데이터에 주소 정보를 붙여서 누구의 것인지 표시
- 수신 측 DEMUX가 주소를 보고 분리
단점
- 매 전송마다 주소를 붙이기 때문에 overhead 증가
- 주소 확인하고 분할하는 과정에서 지연이 발생
- 하지만 bursty한 트래픽 환경에서는 효율이 극대화
(Multi-Channel) Splitting
다중화의 반대 개념
핵심 개념
- Splitting : 하나의 입력을 여러 통로로 나눈다.
동작 원리
- 입력 데이터를 여러 병렬 채널로 분할하여 전송한다.
- 수신 쪽에는 다시 Merge를 통해 원래 데이터로 복원한다.
- 주로 대용량 데이터 전송, 고속 병렬 처리뜽에 활용한다.
통계적 다중화와 패킷 스위칭의 관계
핵심 개념
- 사실상 통계적 다중화와 패킷 스위칭은 핵심 메커니즘이 동일함.
- 패킷 단위로 링크를 공유하기에 “링크 자원을 동적으로 사용하는 것”
세부적인 두 개의 관계
- 패킷 스위칭은 각 데이터(패킷)에 주소 (Address) 정보를 포함한다.
- 서로 다른 출발지 (Source)에서 온 패킷들이 공동 링크를 공유하며 섞인다.
- 송신 전에 스위치가 패킷을 임시 저장 (buffering)하고 이후에 store-and-forward방식으로 전송된다.
- 여러 노드가 동시에 전송을 시도하면 경합이 발생한다.
- 큐에 쌓이고, 지연이 증가한다.
- 버퍼가 넘치면 버퍼 오버플로우 (buffer overflow)가 생기고, 혼잡 (congestion)이 발생한다.
주의할 점
- 통계적 다중화는 항상 효율적이지만, 너무 많은 트래픽이 몰리면 지연과 혼잡이 심화된다.
- 따라서 혼잡 제어 (congestion control)이 필요하다.
참고 : 서킷 스위칭 vs 다중화 관계
- 서킷 스위칭 : 전용 경로 확부 후 계속 사용 (FDM/TDM 기반 고정 다중화)
- 다중화 : 링크를 여러 사용자 간에 나눠 쓰기
=> 따라서 겉보기에는 비슷해 보이지만, 본질이 다르다.
요구 사항 3 : 통신 서비스 제공
핵심 개념
- 통신의 주체는 ‘응용 프로그램’
- 즉 네트워크의 진짜 사용자는 ‘기기 (device)’ 가 아니라 ‘앱 (application)’ 이다.
- 카카오톡, 줌, 넷플릭스 같은 응용이 바로 통신의 클라이언트
- 네트워크는 이 응용들이 원할히 통신할 수 있도록 기능을 제공해야 한다.
- 이를 QoS (Quality of Servie) 측면에서 관리한다.
-
통신 기술은 응용이 요구하는 서비스를 실현하기 위한 기반이 된다.
- 즉, 호스트 (Host) 간 연결을, 프로세스 (process) 간 통신 형태로 변화시키는 것
- 예전에는 단말기 중심의 통신
- 현대 네트워크에서는 한 컴퓨터 안의 특정 프로세스 간 통신이 중심
- 이때 네트워크는 프로세스 간 연결을 위한 채널을 제공한다.
Network Transparency
- 투명성 제공
- 응용이 네트워크 내부의 구조나 위치를 의식하지 않아도 통신이 가능해야 한다.
- 상대방이 어디에 있든 (같은 LAN이든, 지구 반대편이든) 동일한 방식으로 접근 가능하도록 만들어주는 것
통신 장애 극복
- 네트워크는 이상적인 환경에서 항상 정상 동작하지 않는다.
- 전기적, 물리적, 논리적 오류가 발생할 수 있다.
- 따라서 장애를 예측하고 이를 극복하는 기능이 통신 기술의 본질이다.
주요 장애 유형
- 비트 수준 오류 : 전자기 간섭 / 방해
- 패킷 수준 오류 : 충돌, 혼잡
- 링크 / 노드 고장 : 라우터, 케이블의 장애
- 메시지 지연 : 트래픽 과부하
- 메시지 순서 뒤바뀜 : out-of-order
- 데이터 위변조 : 악의적 공격
해결 원리
- 응용이 예상하는 서비스 품질과 실제 네트워크가 제공하는 품질 사이의 간극을 메우는 것
-> 즉 통신 기술의 핵심은 보정
- **통신망의 협조 + 호스트의 소프트웨어 (TCP 등) 로 이루어진다.
여기까지 통신 서비스가 무엇을 제공해야 하는가에 대한 내용이다.
네트워크 구조
프로토콜 (Protocol)
- 통신에 사용되는 ‘약속’ 혹은 ‘규칙’
- 수신/송신 형식, 언어 절차
- 반드시 양쪽이 동일한 약속 (대칭 관계)을 따라야 통신이 가능하다.
프로토콜이 복잡해지는 이유
- 다양한 컴퓨터 시스템과 응용 환경이 존재하기 때문이다.
- 하나의 네트워크에는 수많은 프로토콜이 동시에 작동한다.
- 그 결과 생기는 문제들 종류:
- 복잡성 증가, 불명확한 해석, 변경/확장에 어려움, 새로운 프로토콜이 추가될 때 기존과의 호환성 문제
계층화 (Layer)
프로토콜의 복잡화 문제를 해결하기 위한 구조적 원리
개념
- 복잡한 문제를 한 번에 해결할 수 없기 때문에, 문제를 여러 단계로 나누어서 해결한다. “추상화”
- 각 단계(계층)는 자신의 역할만 수행하고, 그 아래 계층의 세부 구현은 숨긴다.
통신에 적용
- 통신 시스템은 다층 구조로 정의
- 하위 계층은 상위 계층에 서비스를 제공 (service)하고 상위 계층은 하위 계층을 이용 (use) 한다.
- 각 계층은 독립적으로 개발 관리가 가능하다. -> 재사용성과 유지보수성이 증가한다.
프로토콜 계층 / 개체 (Protocol Layer & Entity)
개념
- 전체 시스템을 구성하는 각 계층은 프로토콜의 구성요소 (개체, entity)
- 각 프로토콜의 개체는 두 가지 인터페이스를 가진다:
- 서비스 인터페이스 (Service Interface)
- 바로 위 계층(상위 계층)에 어떤 서비스를 제공하는지 정의
- “무엇을 할 수 있는가?”
- 동료 인터페이스 (Peer-to-Peer Interface)
- 같은 계층의 다른 시스템 (Host) 간 교환되는 메시지 형식 정의
- “어떻게 대화할 것인가?”
- 서비스 인터페이스 (Service Interface)
Host A Host B
┌────────────────────┐ ┌────────────────────┐
│ Application │ │ Application │
│ ↑ Service API │ │ Service API ↑ │
│ ↓ Peer Interface │ ←──────→ │ Peer Interface ↓ │
│ TCP / IP Stack │ │ TCP / IP Stack │
└────────────────────┘ └────────────────────┘
프로토콜 계층 구조 이해
- 통신 프로토콜은 한 덩어리로 만들어지지 않고, 여러 작은 계층으로 나누어 설계된다.
- 이유
- 복잡한 기능을 분리하여 관리하기에 용이하다.
- 각 계층의 기능을 재사용 가능하게 만들기 위해서다.
-
각 계층 자체도 하나의 프로토콜로 볼 수 있다. (recursive 한 구조)
-
전체 통신 프로토콜은 이러한 여러 개의 계층 프로토콜의 조합으로 구성되어 있다.
프로토콜을 계층화한다는 말
-> 작은 프로토콜을 쌓아 올려 하나의 시스템을 만든다는 뜻
- 계층 구조가 필수적인 이유 : 공통적으로 2 부분으로 나눔.
- 통신 약속 부분 : 상대방과의 데이터 교환 규칙을 정의
- 시스템 내부 부분 : 실제 구현 및 하위 계층과의 연동 관리
프로토콜 그래프 (프로토콜 스택이라고 도 함.)
- 프로토콜 그래프란 여러 프로토콜이 계층적으로 연결되어 있는 구조
- 각 계층의 프로토콜은 “상위 프로토콜에 서비스 제공”, “하위 프로토콜을 이용”
- 동료 (peer) 프로토콜 각 통신은 직접이 아닌, 하위 계층을 통해 간접적으로 수행된다.
- 실제 물리적 연결은 하위 계층이 담당, 상위 계층은 위임 형태로 통신을 수행한다.
- 하위 계층을 여러 프로토콜이 공유한다. 다중화 (Multiplexing)
- 반대로, 하위 계층에서 상위 프로토콜로 다시 나눌 때는 역다중화 (Demultiplexing)
- 수신 측에서 어떤 상위 프로세스로 보낼지 구분하기 위한 key (식별자)가 필요하다.
계층적 프로토콜에서의 통신
논리적 통신 (Logical Communication)
- 서로 다른 호스트의 같은 계층 (peer)끼리 통신하는 것처럼 보이는 관계
물리적 통신 (Physical Communication)
- 실제로는 하위 계층 (전송선, 라우터 등)을 거쳐서 물리적으로 전달되는 과정
즉, 논리적으로는 대화하고 있는 것처럼 보이지만, 실제로는 데이터가 계층을 따라 내려갔다가 올라가는 구조이다.
통신 흐름
- 상위 -> 하위 (Send down)
- 응용 계층의 데이터가 하위 계층으로 전달되어 캡슐화된다.
- 하위 -> 상위 (Send to peer)
- 상대방 호스트에서 데이터가 다시 상위 계층으로 올라가 복원 된다.
- 논리적으로는 동료 (peer) 간 통신
- 실제로는 하위 계층 간의 연속적인 릴레이로 이루어진다.
동작 원칙
- 통신은 위에서 아래로, 아래에서 위로 단계적으로 진행된다.
-
각 계층은 자신의 헤더 (header)를 추가하고, 이 데이터를 다음 계층으로 넘겨서 전송한다.
-
수신 측은 반대로 헤더를 읽고 제거 (decapsulation) 하면서 데이터를 복원한다.
- 구성
모든 프로토콜의 공통 동작 원리
- 모든 계층의 기본 구조와 동작 원리는 동일하다.
- 다만 헤더의 내용이 계층마다 다르다.
추상화와 계층화
추상화 (Abstraction)
- 복잡한 시스템을 한꺼번에 다루기 어렵기 때문에, 일부 세부 내용을 감추고 ‘기능만 있다고 가정’하는 사고 방식
-
이 기능은 하위 계층이 알아서 해줄거라고 가정하고 위 계층을 설계하는 것
- 추상화는 세부 구현으로부터 해방되는 것
계층화
- 추상화를 구조적으로 구현한 형태
- 전체 시스템을 여러 계층으로 나누어 각 계층이 담당 기능을 분리 수행하도록 함.
- 하위 계층이 서비스를 제공하고, 상위 계층은 이를 이용하여 자신의 기능을 구현한 뒤 다시 상위에 제공한다.
통신에 있어서 계층화는 필수적이다.
- 통신은 단순히 데이터 전달이 아니라, 논리적 (추상화된) 관점과 물리적 (구체화된) 관점이 모두 필요하다.
표준 구조 (Standard Architectures)
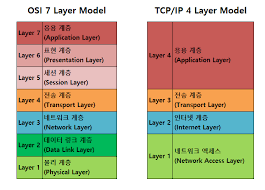
OSI 참조 모델 (Open Systems Interconnection Model)
- ISO (국제표준화기구)에서 제안한 개방형 통신 시스템 구조
- 서로 다른 시스템 간에도 통신이 가능하도록 “계층별 역할”을 표준화한 모델
- 실제 구현이 아니라 통신 구조를 개념적으로 나눈 ‘참조 모델’ (reference model) 이다.
OSI 모델의 의의
- 통신 문제를 단계별로 분리
- 복잡성 감소, 표준화 용이
- 각 계층은 독립적이지만, 하위 계층의 서비스를 이용해 상위 계층의 기능을 구현함.
- 모든 계층은 대칭적 구조로 설계되어, 송/수신 측에서 동일한 기능을 수행할 수 있다.
- 한계점
- 너무 이론 중심적이고, 구현 복잡도가 높다.
- 실제 인터넷 프로토콜은 OSI의 계층을 단순화한 형태로 발전된다. TCP/IP 구조
OSI 7계층 구조
7계층 : 응용 계층 (Application) : 사용자 응용과 직접 연결, 응용 자체와 관련된 사항 처리
6계층 : 표현 계층 (Presentation) : 데이터 표현 방식, 인코딩/디코딩 압축, 암호화 등 처리
5계층 : 세션 계층 (Session) : 통신 세션 (대화) 설정, 유지, 종료 관리
4계층 : 전송 계층 (Transport) : end-to-end 신뢰성 있는 데이터 전달 (TCP)
3계층 : 네트워크 계층 (Network) : 호스트(단말) 간 데이터 전송 및 라우팅 (rout) 담당 (IP)
- 대표 단위 : Packet
2계층 : 데이터링크 계층 (Data Link) : 한 링크 내 노드 간 데이터 전송 및 오류 검출
- 대표 단위 : Frame
1계층 : 물리 계층 (Physical) : 전기적 신호(비트) 전송 및 물리적 매체 제어
- 대표 단위 : Bit
인터넷 (TCP/IP) 구조
-
IETF (Internet Engineering Task Force)가 제안한 실제 인터넷 프로토콜 구현 구조
-
OSI 7계층처럼 나누지 않고, 4계층으로 단순화 되어있다.
OSI 보다는 실용적이고 효율적이다.
설계와 구현이 병행되어 있어서 실제 인터넷의 기반이 된다.
-
계층 간 경계가 유연하다. 필요한 경우 일부 기능이 중첩이 가능하다.
-
모래 시계 구조로 중간 IP는 단일 표준, 상하위는 다양하기에 확장성이 높다.
TCP/IP 4계층 구조
4계층 : 응용 계층 (Application) : 사용자 서비스 담당
3계층 : 전송 계층 (Transport) : end-to-end 신뢰성 / 비신뢰성 데이터 전송
2계층 : Internet 계층 : 경로 설정 및 패킷 전달
1계층 : Network Access (Link) : 물리적 연결 및 프레임 전송
요약
OSI 모델의 목적과 의의
- 컴퓨터 네트워크의 설계와 구성을 위한 구조적 체계 표준
- 실제 구현 모델이 아닌, 통신 시스템을 이해하고 설계하기 위한 참조 모델
- 문제 인식과 설계 개념 정립용 모델
- 통신에 필요한 모든 기능과 기술 요소를 7개의 계층 구조로 분리 배치
- 하위 계층의 서비스는 상위 계층이 사용하고, 상위 계층의 기능을 지원하는 추상화된 구조
성능
성능1 : 대역폭 (Bandwidth)
대역폭 = 처리량 / 처리속도 (Throughput)
- 대역폭은 물리적으로 지원이 가능한 최대 데이터 전송 용량 (이론치)
- 처리량은 실제 전송된 데이터의 양 (실측값)
- 네트워크의 혼잡, 오류 재전송, 대기 등에 따라서 실제 처리량은 줄어든다.
- 즉, Bandwitch >= Throughput
개념
- 단위 시간당 전송될 수 있는 데이터 양
- 얼마나 많은 비트를 1초에 보낼 수 있나
- 단위 : bps (bits per second)
- 10 Mbps = 10 megabits per second = 10^^6 bits/sec
- bit width (비트 폭) : 각 비트가 차지하는 시간 가격
- 전송 속도가 빠를수록 bit width가 좁아진다.
성능2 : 소요시간 (Latency) / 지연시간 (Delay)
- 한 지점 (A)에서 다른 지점 (B)로 메시지를 송신하는데 걸리는 시간
- 단위 : millisecond (ms) 또는 microsecond(μs)
- 왕복지연시간 (RTT, Round Trip Time) : 왕복에 총 걸리는 시간
소요시간 구성요소 \(\text{소요시간} = \text{전파지연(Propagation)} + \text{전송지연(Transmission)} + \text{큐잉지연(Queue)} + \text{처리지연(Processing)}\)
- 전파지연 (Propagation Delay) : 신호가 매체를 따라 이동하는데 걸리는 시간 (거리 / 전파속도)
- 전송지연 (Transmission Delay) : 데이터를 송신장치가 모두 내보내는 데 걸리는 시간 (데이터 크기 / 대역폭)
- 큐잉지연 (Queueing Delay) : 중간 노드에서 대기하는 시간 (네트워크 혼잡 시 증가)
- 처리지연 (Processing Delay) : 라우터/노드가 헤더를 읽고 처리하는 시간 (일반적으로 매우 짧음)
거리가 멀수록 전파지연시간은 증가하지만, bandwitdh에는 영향이 없다. (둘은 별개의 metric임)
Timing
Timing in Circuit Switching
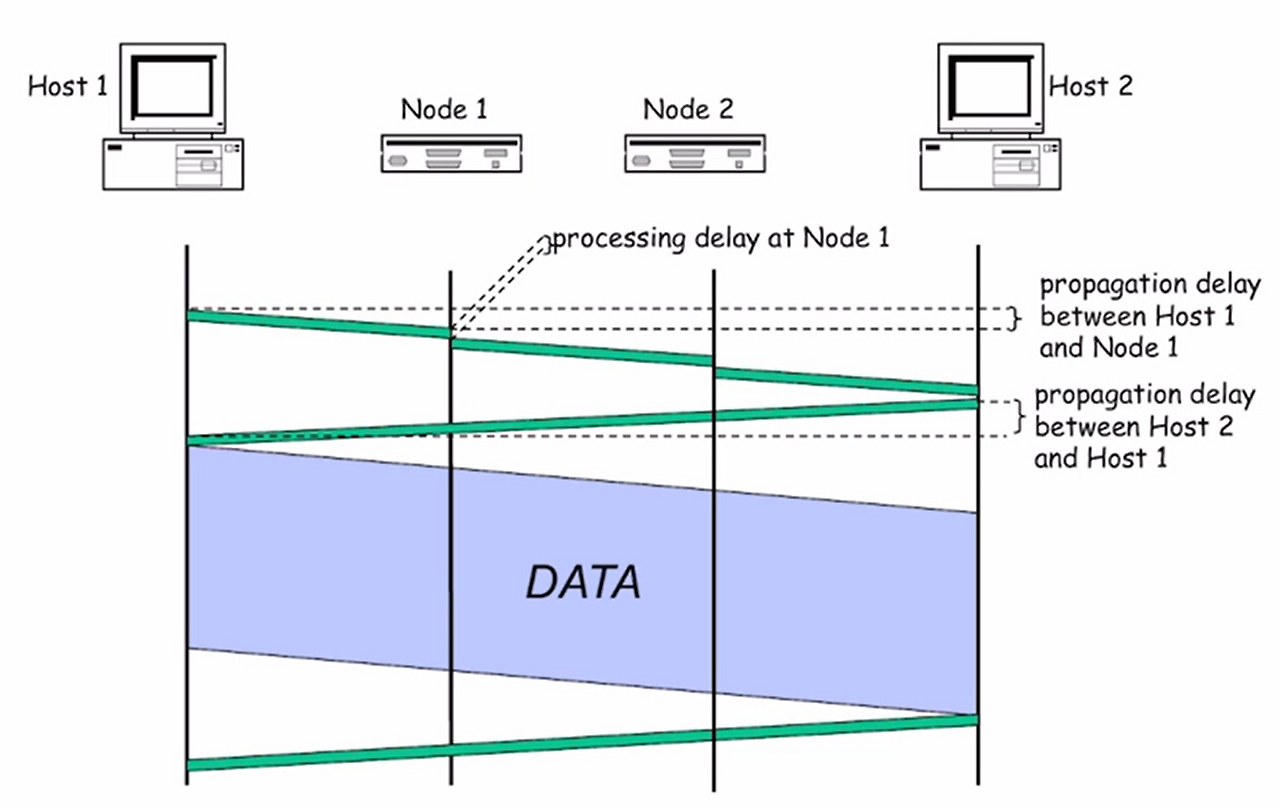
회선교환 (Circuit Switching) : 송신자-수신자 간 전용 회선을 설정 후에 데이터를 전송한다.
-
전화망 방식이 대표적
-
전체 통신 시간은 3단계로 구성
- 회선 설정 -> 데이터 전송 -> 회선 해제
시간 구성도 해석
- Setup 단계 : 회선을 예약하느라 지연이 발생 (Connection Setup Delay)
- Data Transmission : 한 번 확보된 경로를 따라서 연속적이고 안정적인 데이터 전송이 가능하다.
- 전송 시간 총합 : 전파지연시간 X 거리 + 전송지연시간
Timing in Packet Switching
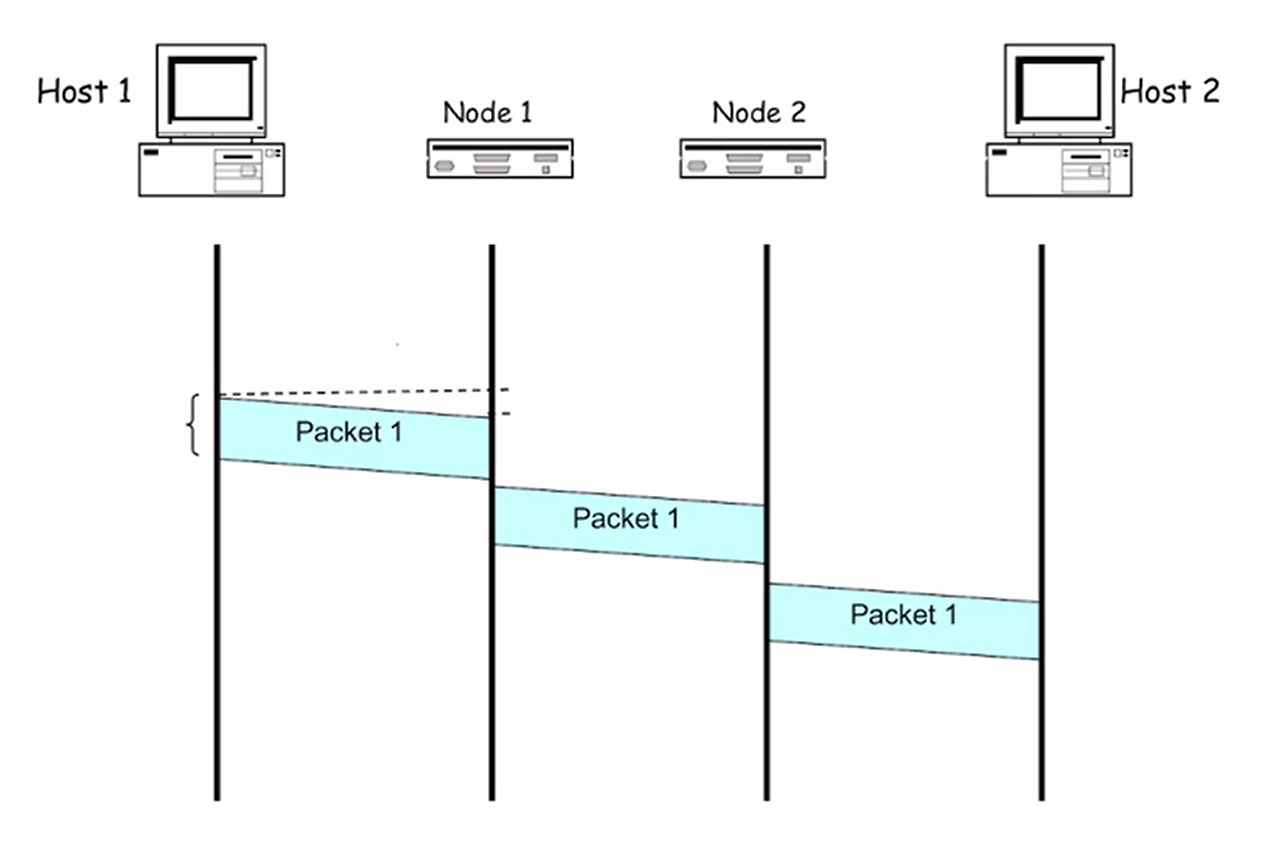
패킷 교환 (Packet Switching) : 데이터를 작은 조각 (패킷)으로 분할하여 전송
-
각 라우터 (Node)는 패킷을 받고 (Store) 처리 후 다음으로 전달 (Forward) 한다.
이 과정을 Store & Forward (S&F)라고 부른다.
-
전 구간 (end-to-end)에 회선을 미리 예약하지 않는다.
-
각 노드가 자율적으로 패킷을 저장하고 전달하기에 유연하다.
-
단, 각 노드마다 누적 지연이 생긴다.
동작 과정
- Host1 이 Packet 1을 전송을 시작한다.
- Node1은 패킷 전체를 다 받은 후에야 다음 구간으로 전송을 시작한다.
- 비트 단위가 아니라 패킷 단위로 처리한다.
- 각 노드를 지날 때마다 아래의 지연이 누적된다.
- 전파지연, 전송지연, 처리지연, 큐잉지연
회선 교환 VS 패킷 교환
- 회선 교환 : 일관된 속도, 예약 기반
- 패킷 교환 : 유연한 경로, 공유 기반
Packet Segmentation : Pipelining
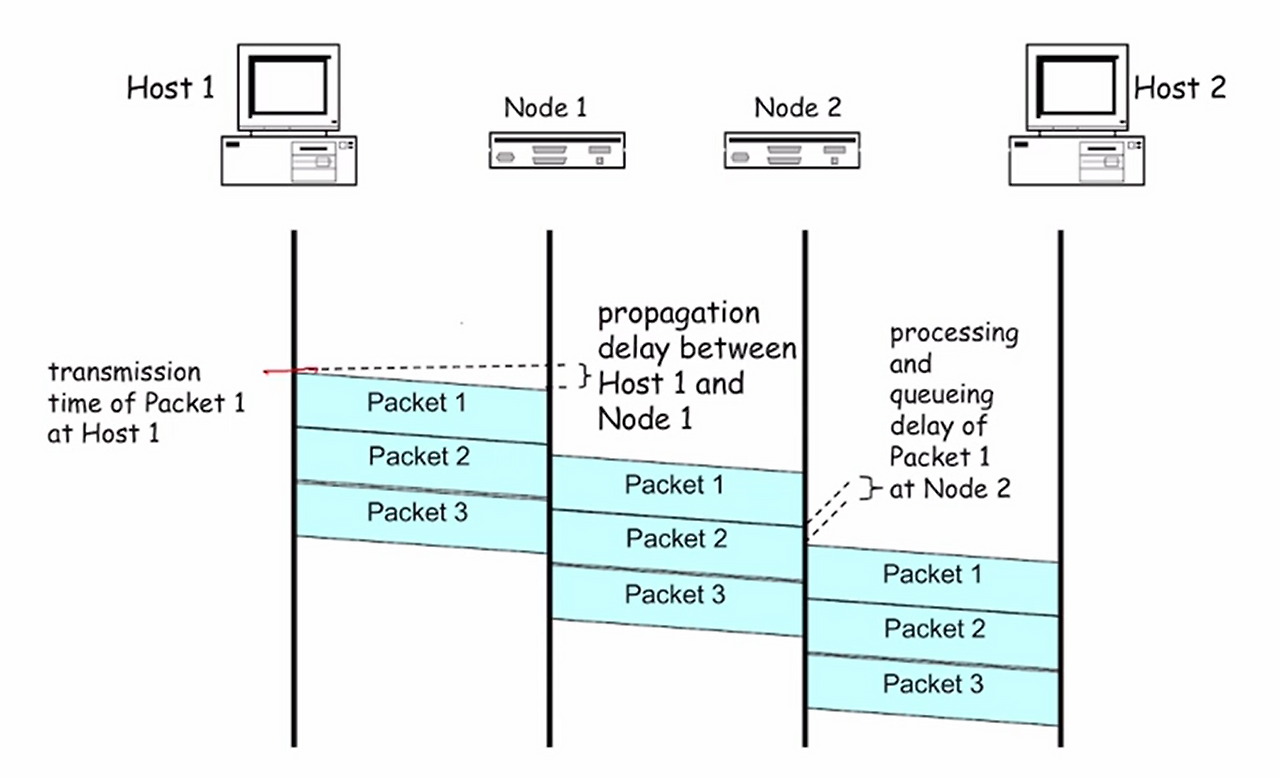
- 전체 메시지를 여러 개의 작은 패킷으로 분할 (Segmentation)
- 각 패킷은 독립적으로 동시에 전송될 수 있다.
- Pipelining 효과가 발생한다.
- 그림에서 첫 번째 패킷은 여전히 Store & Forward 과정을 거치지만, 그 뒤 패킷들은 동시에 여러 구간에서 병렬 전송이 된다. => 결과적으로 총 소요시간이 비례적으로 감소한다.
패킷을 작게 만드는 것이 유리할까?
- 패킷을 작게 만들면 지연 겹침 (Pipelining) 덕분에 전송 효율이 증가한다.
- 하지만 너무 작게 나눈다면, 헤더 오버헤드가 증가해서 비효율적이다.
성능 : 추가적 참고 지표
1) 대역폭 vs 소요시간의 상대적 중요성
-
작은 메시지는 소요 시간 (Latency) 가 중요하다.
-
큰 메시지는 대역폭 (Bandwidth)가 중요하다.
-
실효 처리랑 (Throughput)
- 회선 스위칭
- 패킷 스위칭
- 큐잉 / 처리 지연까지 섞여서 더 커질 수 있다.
2) 대역폭 X 지연시간 = BDP (Bandwidth-Delay Product)
-
BDP는 링크 파이프 안에 동시에 떠 있을 수 있는 최대 비트 수 \(\text{BDP (bits)} = \text{Bandwidth (bits/s)} \times \text{RTT (s)}\)
-
링크의 길이를 ‘비트 길이’ 로 본 값 : 파이프 용량 (버퍼 요구량) 의 척도
-
윈도 크기 / 버퍼 크기의 설계의 기준
3) 프레임 전송의 시간적 이해 (Stop - and -Wait 직관)
- 프레임 하나 보내고 ACK기라디는 전송
- 대역폭만 10배 올리고 프레임 크기와 RTT가 같다면
- 효율이 낮다. (링크가 놀고 있기 때문)
- 해결책 : 프레임을 키우거나, 슬라이딩 윈도우/파이프라이닝으로 동시에 여러 프레임 전송
4) 성능 : 기타 사항
- 메시지가 너무 짧으면 대역폭은 의미가 작음. (RTT가 지배)
- 총 소요시간에는 네트워크만이 아니라 호스트 소프트웨어 처리도 포함
- 거리가 짧고 링크가 매우 고속일수록 소프트웨어 오버헤드 병목이 되기 쉽다.