FreeSpace Management & Paging
이번 포스트는 OS의 Free Sapce Management 와 Paging 에 대해 다룬다.
FreeSpace Management
Splitting
요청된 메모리 크기보다 free chunk (빈 공간) 가 더 클 때, 그 큰 free chunk를 둘로 쪼개서 하나는 할당하고, 나머지는 free list에 남기는 기법
- 목적
- 너무 큰 free chunk 하나가 있을 때
- 그 중 일부만 사용하고 나머지는 free list에 계속 남김
- 장점 : 메모리의 낭비 없이 효율적으로 사용이 가능하다.
- 단점 : 조각난 free chunk가 많아지면 external fragmentation(외부 단편화)가 발생이 가능하다.
Splitting 예시
-
전체 heap : 30bytes
-
구조
0~10: free 10~20: used 20~30: free -
free chunk 2개
- addr = 0, len = 10
- addr = 20, len = 10
-
free list의 구조
head → [addr:0, len:10] → [addr:20, len:10] → NULL
작은 요청에 대한 Splitting 과정
- free chunk 2개 (위와 같은 상황)
- 요청 (request) 크기 : 1byte
- 과정
- free list 첫 번째 chunk(0~10)을 확인
- 요청 크기 = 1, free chunk 크기 = 10 -> 분할이 필요함
- free chunk를 두 조각으로 나눔:
- 1 byte - 할당
- 9 byte - free chunk로 남김
- Heap 결과
free(0~1) → used(10~20) → free(21~30)
- Free list 변화
head → [addr:0, len:10] → [addr:21, len:9] → NULL
Coalescing
- 반대로 사용자가 요청한 메모리 크기보다 free chunk가 작으면 할당이 불가능하다.
- Coalescing (병합) : 반환된 free chunk가 기존 free chunk들과 주소상 인접해 있으면 하나의 큰 chunk로 합친다.
- free chunk가 여러 개로 잘게 쪼개져 있으면 큰 요청을 처리하지 못함. (외부 단편화 문제)
- 붙어 있는 free chunk들을 합치면 큰 free chunk가 만들어져 큰 요청을 처리가 가능하다.
Coalescing 예시
- free list에 3개의 chunk가 존재:
- addr = 10, len : 10
- addr = 0, len : 10
- addr = 20, len : 10
- 결과적으로 0~30 범위의 하나의 큰 free chunk (len : 30)으로 병합이 가능하다.
Tracking The Size of Allocated Regions
free (void * ptr)은 크기 (size)를 인자로 받지 않는다.- 그럼 free할 때 해당 메모리 블록의 크기를 알까?
- malloc은 사용자 요청한 공간 앞에 header를 붙여서 metadata를 저장함.
Header
Header 가 하는 역할
- size : 이 블록이 갖는 데이터 영역의 크기
-
free(ptr)실행 시 ptr 바로 앞을 보면 header 가 있으므로 이 사이즈를 읽어 free list에 되돌릴 수 있다. - 예시
- 사용자가
malloc(20)을 호출 -> 20 바이트 + header 크기 만큼 확보 - ptr은 데이터 영역을 가리키고, Header는 그 바로 앞에 존재
- 사용자가
size 외에도 하는 일들
- magic number : 메모리 손상 여부를 체크한다.
- extra pointers : 빠른 free 작업을 위해 (예 : double linked list 구조)
- 실제 malloc(N) 에서 확보하는 크기 = N + header 크기
코드 구현
typedef struct __header_t {
int size;
int magic;
} header_t;
free(void *ptr)을 실행할 때:
header_t *hptr = (header_t *)ptr - 1;
- ptr바로 앞에 (-1) header 가 있으므로 위와 같이 접근할 수 있다.
Embedding A Free List
문제점
- 일반적인 프로그램은 free list에 노드를 추가하기 때문에
malloc()을 호출하지만, - 메모리 할당기(malloc) 구현체는
malloc()을 사용할 수가 없다.- 자기 자신을 만들 때 자기 자신을 다시 이용할 수 없기 때문이다.
해결 방법
- 메모리 할당기는 자신만의 heap을 직접 초기화하고,
- 그 heap 공간 내부에 첫 free list node를 만들어 둔다.
-> free list는 heap 안에 직접 저장되는 구조다.
Free list의 Node 구조
typedef struct __node_t {
int size;
struct __node_t *next;
} node_t;
- 각 free chunk는 다음 정보를 가짐.
- size : 이 free chunk의 크기
- next : 다음 free chunk를 가리키는 포인터
-
Heap을 만들고 첫 free list을 만드는 과정
node_t *head = mmap(NULL, 4096, ...); head->size = 4096 - sizeof(node_t); head->next = NULL;- 4096 Byte를 할당받았다면:
| 내용 | 크기 |
|---|---|
| free list header (node_t) | 8 bytes |
| 남은 공간 | 4088 bytes |
첫 free chunk
- 시작 주소 : head
- free 공간 : 4088 bytes
- next = NULL
Heap 전체가 free 상태가 된다.
Allocation
- 메모리를 요청받으면 어떻게 할까?
할당기는 다음과 같은 역할을 한다
- free list에서 충분히 큰 chunk를 찾는다.
- 그 chunk를 두 개로 split
- 첫 번째 : 요청된 크기 + 헤더
- 두 번째 : leftover chunk
- free list의 크기를 줄이거나, leftover chunk를 다시 free list에 삽입
예시 : 요청 malloc(100)
- malloc은 100byte를 사용자에게 주지만,
- header의 포함 크기는 108 bytes
- 할당 후 상태
- 첫 108 bytes를 할당
- header (size = 100, magic = 1234567)
- 뒤에 100 bytes를 사용자에게 제공
- 나머지 공간은 새로운 free chunk
- 크기 : 4088 - 108 = 3980 bytes
- 첫 108 bytes를 할당
Free
free (sptr)을 호출할 때
1) free()는 sptr에서 header의 위치를 찾는다.
header_t* hptr = (header_t*)sptr - 1;
- malloc은 payload 주소를 return 하기 때문
- header는 그 바로 “앞”에 있다.
2) free된 chunk를 free list의 “head”로 삽입한다.
- free list는 LIFO (스택) 형태로 유지
void* tmp = head;
head = (header_t *)sptr - 1;
head->next = tmp;
- 새로 freee된 chunk를 리스트 가장 앞으로 넣음.
- 기존 head는 2번째 노드로 이동
아직은 coalescing 이 일어나지 않은 단계
- free space는 총 3864 bytes가 존재하지만,
- 100 + 3764
- 아직 free chunks는 분리되어 있는 상태
-> 결과적으로 나머지 allocated chunk 들도 모두 free된 이후
- Free 리스트의 모양
head → [size:100]
↓
[size:100]
↓
[size:100]
↓
[size:3764]
모두 free space인데, 연속된 free chunk임에도 불구하고, free list에서는 각각 따로 관리되고 있다.
- 외부 단편화 발생
- 해결 방법 : Coalescing (병합)
Growing the Heap
대부분의 메모리 할당기는 처음에 작은 힙을 갖고 시작한다.
그리고 힙 공간이 꽉 차면 OS에게 더 많은 힙 공간을 요청한다.
UNIX 계열에서는 다음 시스템 콜을 사용
- sbrk() / brk() : 힙의 끝 포인터를 조정해 힙을 늘림
- 힙은 위로 증가하는 구조
- break 포인터가 움직이면서 힙이 확장
- 물리 메모리에서도 연속된 범위가 확보되면 힙을 확장해준다.
Managine Free Space
Basic Strategies
Best Fit
- 요청 크기 이상인 Free chunk들 중 가장 작은 free chunk를 선택
- 메모리를 아끼기 위한 방식
- 장점 : 남은 공간이 최소라서 fragment가 줄어든다.
- 단점
- 매번 전체 리스트를 탐색해야 하기 때문에 느리다.
- 너무 잘게 잘려서 작은 조각들이 많이 생기는 단점도 있다.
Worst Fit
- free chunk 중에서 가장 큰 chunk를 선택
- 큰 chunk를 쪼개고 남은 부분은 다시 free list로 돌려놓음.
- 장점 : 큰 공간이 남아 있어 fragment 를 덜 만든다고 기대
- 단점 : 실제로는 메모리 사용 효율이 썩 좋지 않다.
First Fit
- free list에서 처음 발견되는 충분히 큰 chunk를 선택
- 빠르고 효율적 (탐색 중단)
- 단점 : 앞부분에 작은 조각들이 계속 쌓여 -> fragmentation 유발
Next Fit
- First Fit의 변형으로 이전 탐색이 멈춘 지점부터 다시 탐색
- free list의 시작부터 확인하지 않고, 마지막 본 위치에서 계속 탐색
- 처음부터 매번 탐색을 안해도 됨.
- 단점 : 성능이 상황에 따라 들쭉날쭉함.
Other Approaches
Segregated List
일종의 크기 별로 나뉜 여러 개의 free list 구조
- 같은 크기의 요청이 자주 들어오면 그 크기만 모아서 따로 free list를 만듦.
- 장점
- 즉시 필요한 크기 리스트로 이동하면 되기에 검색 속도가 매우 빠르다
- 내부 구조가 단순하다.
- 단점
- 각 크기별로 얼마나 메모리를 배정해야 하는가?
- 너무 빨리 고갈 or 너무 많은 공간 할당으로 낭비 가능성이 존재
- Slab Allocator가 이 문제를 해결 : 커널에서 많이 쓰는 방식
- 각 크기별로 얼마나 메모리를 배정해야 하는가?
Slab Allocator
- 커널에서 자주 사용하는 객체들을 위한 전용 캐시를 만들어 놓는 방식
- 예) 파일 시스템 inode 객체, 락 객체, 네트워크 패킷 구조체
- 이 객체들은 자주 생성/삭제되고, 크기도 일정하다.
특징
- 커널 객체 단위로 캐시 운영
- 예 : inode 객체 100개짜리 캐시 할당하여 미리 초기화를 해둔다.
- 캐시가 부족하면 일반 allocator에게 요청
- 예 : Slab이 다 차면
brk() / mmap()로 새로운 메모리를 가져온다.
- 예 : Slab이 다 차면
- 매우 빠른 재사용
- 객체 초기화 비용 감소
- 파편화 감소
Buddy Allocation
- 메모리를 절반씩 나누며 크기가 맞는 블록을 찾는 방법
- 시작 64 -> 32 -> 16 -> 8 -> 4….
- 장점 : 블록 크기가 2의 제곱수라 병합(coalescing)하기 매우 쉽다. 빠른 할당 / 해제가 가능
- 단점 : 내부 단편화가 발생한다.
# Paging : Introduction
Paging
개념 : 주소 공간을 page 라는 고정 크기 단위로 쪼개는 방식
Segmentation과의 비교 :
- Segmentation : code / stack / heap 같은 가변 크기 영역
- Paging : 고정 크기 page 단위
- Physical memory도 동일하게 분할
- 실제 물리 메모리도 page 크기와 같은 고정 크기 단위로 나뉜다.
- page frame이라고 부른다.
- Page Table의 역할
- 프로세스마다 Page Table을 유지
- 가상 주소의 page 번호 (VPN, Virtual Page Number)를 물리 주소의 page frame 번호(PFN)에 매핑하는 역할
: 즉 Paging은 고정 크기 단위로 가상/물리 메모리를 쪼개고, Page Table이 매핑 작업을 담당하는 구조이다.
Paging의 장점
1. Flexibility : 주소 공간 추상화를 매우 유연하게 지원
- heap이 위로 늘고, stack이 아래로 자란다는 패턴을 예측할 필요가 없다.
- 그냥 필요한 page만 물리 메모리 어느 frame에든 매핑하면 되기 때문
2. Simplicity : Free-space의 관리가 매우 쉬움
- Free-space 관리가 매우 쉬움
- 모든 page 의 크기가 동일하기 때문에
- 단순히 ‘빈 page frame’ 리스트만 유지하면 되기 때문에
- Segmentation처럼 크기 다른 hole을 조정할 필요가 없다.
Paging Table
-
Page Table은 ‘데이터 구조’
- 가상 주소 -> 물리 주소 변환에 필요한 정보를 담은 테이블
- 가장 단순한 형태로 Linear Page Table (배열 구조)
-
각 프로세스는 자신의 Page Table을 가진다.
- PCB(Process Control Block) 안에 Page Table Base Register (PTBR)로 시작 주소를 가리킨다.
-
Page Table은 엄청 커질 수 있다.
- 예시)
- 32-bit virtual address space
- Page 크기 = 4KB (=3.906KiB )
- VPN bit 수 = 32-12 = 20 bits
- 엔트리 개수 = 2^20 = 약 100만 개
-> Page Table 크기 = 1M entries x 4 bytes = 4MB
프로세스 하나당 4MB의 Page Table 이 필요하다는 뜻으로 비효율적이다.
Address Translation
주소는 2가지의 부분으로 나뉜다.
- VPN (Virtual Page Number)
- Offset (페이지 내 위치)
예시) 64 바이트의 가상 주소 공간일 때
- 총 64바이트 -> 6비트 주소가 필요
- 페이지 크기 16바이트 -> offset : 4 비트
- 남는 2비트 -> VPN
[Va5 Va4] [Va3 Va2 Va1 Va0]
VPN Offset
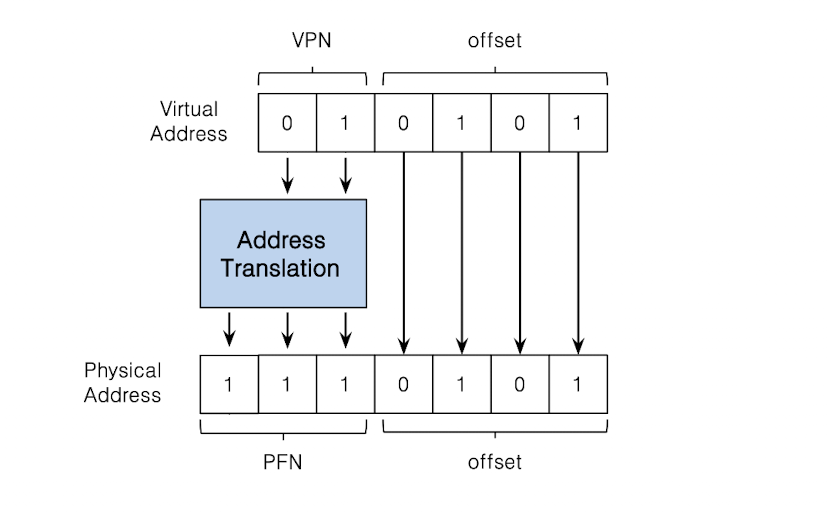
단계
1. Virtual Address 분석
- VA = 21(010101)
- VPN = 01 (1번 페이지)
- offset : 0101 = 5
2. Page Table Lookup
- 테이블 페이지에서 VPN 1 -> PFN 7로 가리킨다고 가정하면
- 1번 가상 페이지는 물리 프레임 7에 저장된다.
3. Physical Address 생성
- Physical Address = PFN + offset
- PFN(7) = 2진수 11
- Offset = 0101
Page Table Entry
Valid Bit
- 해당 PTE(Page Table Entry)가 유효한 변환인지를 나타내는 비트
- Valid = 1
- 가상 주소(VA)가 실제 메모리의 물리 주소(PA)로 매핑됨.
- Valid = 0
- 이 페이지는 유효하지 않음 (사용하지 않는 영역, 권한 X, Page Fault 발생)
Protection Bit
- 페이지에 대한 읽기, 쓰기, 실행 (Read, Write, Execute) 권한을 표시
- 예: Read-only-page에서 Write이 발생하면 fault를 발생
Present Bit
- 페이지가 현재 물리 메모리에 있는지 여부를 표시
- Present = 1 (물리 메모리에 존재)
- Present = 0 (디스크 영역에 있어서 페이지 폴트 발생 시 RAM으로 로드 필요)
Dirty Bit
- 페이지가 메모리에서 수정되었는지 기록
- Dirty = 1 (페이지를 디스크로 내릴 때 write-back이 필요)
- Dirty = 0 (내용이 안바뀌기에 디스크에서 다시 읽을 수 있으므로 저장을 안 해도 된다.)
Reference Bit
- CPU가 최근에 이 페이지에 접근했는지를 표시
- 페이지 교체 알고리즘 (LRU 근사)에서 사용
- 접근되면 1로 바뀌고, 오래 안쓰이면 교체 후보
x86 에서도 위와 같은 핵심 Flag Bit이 존재
그 외의 것들
- U/S (supervisor bit) : 사용자 (User) 모드 접근 가능 여부
- 0 : kernel만 접근
- 1 : user mode 접근 가능
- A (Accessed bit) : 접근 기록 (메모리 읽기/쓰기하면 1)
- PWT, PCD, PAT, G (3~8 bit 영역)
- CPU 캐싱 정책과 관련된 옵션들
- PWT/PCD = 페이지 캐싱 방식
- PAT = Page Attribute Table , 고급 캐싱 설정
- G = Global Page (context swtich시 TLB flush 안함)
Paging
Paging의 단점 : 메모리의 접근이 느려진다.
1. Page Table 시작 주소를 먼저 알아야 한다.
- 가상 주소를 변환하기 위해:
- Page Talbe Base Register (PTBR or CR3) 확인
- 해당 테이블에서 해당 페이지 번호(VPN) 위치 찾기
- 즉, 주소 변환을 위해 추가적인 메모리 접근이 필요함.
2. 매 메모리 접근마다 추가 메모리 접근이 필요하다.
- 원래 메모리 접근 : 1번
- 페이징 사용 시
- PTE lookup (page Table 접근)
- 실제 메모리 접근
- 총 2번의 접근으로 속도가 절반으로 느려지는 효과가 발생