AI - Machine Learning
본 포스트는 Stuart Russell 과 Peter Norvig의 Artifical Intelligence : A Modern Approach (4th edition) 의 Machine Learning부분을 다룬다.
Machine Learning
Q-Learning 을 어떻게 확장할 수 있을까?
문제 상황 :
- 기본 Q-Learning은 tabular method : 상태(state)마다 Q값을 표에 저장
- tabular method : 표 기반 방법
- Atari게임과 같이 픽셀 수가 엄청 많다면 불가능
해결 방향 : 일반화 (Generalization) : Machine Learning의 핵심 아이디어
- 이전 경험을 새롭게 비슷한 상황에 적용
Approximate Q-Learning
- Q값을 표에 저장하는 대신, 선형 함수로 근사하는 방법
피처 (feature) 예시
- f1(s,a) = 행동 a 후 가장 가까운 음식까지의 거리
- f2(s,a) = 행동 a 후 가장 가까운 유령까지의 거리
장점 : 경험을 소수의 강력한 숫자(가중치 w)로 압축
단점 : 피처 품질에 크게 의존, 비슷한 피처 표현 ≠ 항상 비슷한 상태값
AI의 History
| 연도 | 기술 | 적용 도메인 |
|---|---|---|
| 1989 | Q-learning | Gridworld (10~100 states) |
| 2015 | DQN | Atari (10^16992 pixels) |
| 2016 | AlphaGo | 바둑 |
| 2023 | RLHF | ChatGPT |
Machine Learning 이란?
정의 : 데이터나 경험으로부터 특정 작업을 수행하는 모델을 휙득하는 과정
- 모델이란?
- 입력 x를 받아 출력 y를 내는 함수 f
f: x-> y
Supervised Learning (지도학습)
Machine Learning 중에서 가장 기본적인 형태 : 지도학습 (Supervised Learning)
회귀 (Regression)
- 출력 y가 실수값
y ∈ ℝ - 예시 : 방 수 -> 집 값 예측
분류 (Classification)
- 출력 y가 클래스 레이블,
y ∈ {label₁, label₂, ...} - 예시 : 이메일 -> 스팸 여부
Linear Regression
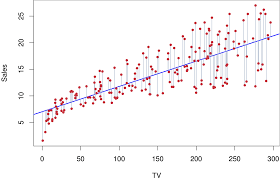
지도학습 파이프라인
훈련 데이터 → 모델 획득(training) → 평가(prediction)
선형 모델 \(\hat{y}_i = f_{\mathbf{w}}(x_i) = \mathbf{w} \cdot \boldsymbol{\phi}(x_i)\)
- 파라미터:
- 특징 추출기:
- 결과적인 Linear Model 식
모델 공간
- 가능한 선형 모델은 무한히 많다.
ℱ = {f_w : w ∈ ℝ²}
- 어떤 w가 좋은지 평가 기준이 필요하다.
가장 좋은 w를 어떻게 찾을까?
손실 함수(Loss Function)
모델의 품질을 어떻게 수치로 측정하는가? 에 대한 수치화된 기준
- 모델이 예측한 값과 실제 정답값 사이의 차이 = 즉 오차(error)가 작을수록 좋은 모델이라고 보는 것 (= 잔차 (residual))
MSE (Mean Squared Error) : 가장 많이 쓰는 손실 함수
- 단순히 오차를 그냥 더해버리면 양수 오차와 음수 오차가 서로 상쇄되는 일 발생
- 오차를 제곱해서 양수로 만들어 더하는 방법을 사용
- MSE / L2 손실이라고 함.
TrainLoss(w)를 최소화하는 w를 찾는 것 \(min_w TrainLoss(w).\)
Solution 1. 최소제곱법 (Least Squares)
-
손실 함수 w를 미분해서 0이 되는 지점을 직접 구하는 방식
-
w를 대수적으로 풀면 닫힌 형태의 해(closed-form solution)가 존재 \(\mathbf{w}^* = (\mathbf{X}^{\top}\mathbf{X})^{-1} \mathbf{X}^{\top}\mathbf{y}\)
-
문제점 : 훈련 데이터가 많아지면 엄청나게 느려진다.
Solution 2. 경사하강법 (Gradient Descent)
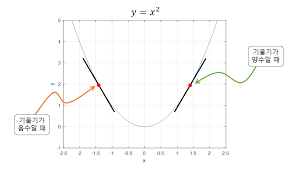
Gradient : ∇_w f(w)는 함수 f(w)의 기울기
-
어떤 방향으로 움직일 때 함수 값이 가장 빠르게 증가하는지를 나타내는 벡터
-
그래디언트가 값이 증가하는 방향을 가리키니까, 반대로 값이 감소하는 방향은 -그래디언트
- 매 스텝마다 그래디언트의 반대 방향으로 조금씩 이동
- 현재 위치에서 기울기가 양수 : 왼쪽으로 이동
- 현재 위치에서 기울기가 음수 : 오른쪽으로 이동
- 매 스텝마다 그래디언트의 반대 방향으로 조금씩 이동
경사 하강법의 알고리즘 전체 구조
Initialize w (예: w = [0, 0])
While not converged:
w ← w − α · ∇_w TrainLoss(w)
- α : 학습률 (Learning Rate)
- 한 스텝에서 얼마나 크게 이동할지를 결정하는 하이퍼파라미터
-
체인룰 (chain rule)
- 예측값 - 실제값 : 오차
- 오차가 크면 그래디언트도 커서 가중치를 많이 수정하고,
- 오차가 작으면 가중치를 조금만 수정하는 구조
- 예측값 - 실제값 : 오차
\[w_n \leftarrow w_n + \alpha \Bigl[ R + \gamma \max_{a'} \hat{Q}(s',a') - \hat{Q}(s,a) \Bigr] f_n(s,a)\]Approximate Q-Learning
- 경사하강법의 특수한 형태 : (예측값 - 실제값)에 해당하는 항에 피처를 곱하고, 학습률 α를 곱해서 가중치 업데이트
고차원 가중치
- 파일이 여러 개일때도 같은 방법이 통한다.
- 파라미터 공간이 2차원에서 M + 1차원으로 커졌지만, 그래디언트 계산공식은 완전히 동일하다는 것
업데이트 품질을 결정하는 세 가지 요소
1. 업데이트 방향
- ∇_w TrainLoss(w)가 결정
- 그래디언트가 정확할수록 올바른 방향으로 이동
2. 업데이트 크기
- 그래디언트의 크기와 학습률이 함께 결정
- 너무 크면 발산하고, 너무 작으면 수렴이 느리다.
3. 한 번의 업데이트 속도
- TrainLoss의 그래디언트를 계산하는데 걸리는 시간이 결정
- 데이터가 많으면 계산 자체에 시간이 많이 걸림
Batch GD
- 안정적이지만 느리다.
- 매 업데이트마다 전체 훈련 데이터를 다 써서 그래디언트를 계산하고, 가중치를 한 번에 업데이트
- 장점 : 그래디언트 방향이 매우 정확하고 안정적 / 노이즈 없이 올바른 방향을 가리킴
- 단점 : 데이터가 수백만 개라면 단 한번의 업데이트를 위해 수백만 개의 샘플을 다 계산해야 함.
SGD (Stochastic Gradeint Boosting)
-
확률적 경사하강법 : 매 업데이트 마다 훈련 데이터에서 샘플 1개만 랜덤하게 뽑아서 그래디언트 계산하고 즉시 업데이트
-
알고리즘
Initialize w
While not converged:
For (x, y) in shuffle(D_train):
w ← w − α · ∇_w Loss(x, y, w)
- 장점 : 업데이트가 엄청 빠르다.
- 단점 : 노이즈가 매우 크다. -> 업데이트 방향이 매번 크게 흔들리기에 최솟값에 수렴하지 못하고 발산할 수도 있다.
Mini-batch GD
실제로 가장 많이 쓰이는 방식
- 전체 데이터가 아니고 샘플 1개도 아닌, 작은 묶음 단위로 그래디언트를 계산
- 알고리즘
Initialize w
While not converged:
D_shuffled = shuffle(D_train)
Split into mini-batches B₁, B₂, ..., Bₖ
For B in [B₁, ..., Bₖ]:
TrainLoss(w) = (1/|B|) · Σ₍ₓ,ᵧ₎∈B Loss(x,y,w)
w ← w − α · ∇_w TrainLoss(w)
- 배치 사이즈 : GPU 메모리와 계산 효율을 고려해서 계산
손실 함수의 선택 : L1 vs L2
- 손실 함수를 바꾸면 학습이 어떻게 달라지는가?
L2 손실 (MSE) \(\operatorname{Loss}(x,y,\mathbf{w}) = \left( f_{\mathbf{w}}(x)-y \right)^2\)
\[\nabla_{\mathbf{w}} \operatorname{Loss} = 2 \left( \mathbf{w}\cdot\boldsymbol{\phi}(x)-y \right) \boldsymbol{\phi}(x)\]L1 손실 (MAE)
- 여기서 sign 함수는 입력이 양수면 +1, 음수면 -1, 0이면 0을 반환
(Linear) Classification
Classification : 주어진 입력 데이터를 보고 그것이 어떤 레이블에 속하는지를 맞히는 문제
-
예시 ) Spam Filter, Digit Recognition
-
분류의 3단계
- 훈련 데이터(Training Data) : 정답이 붙어 있는 데이터를 준비
- 모델 휙득(Model Acquisition) : 이 훈련 데이터를 통해 분류함수 f를 학습
- 추론(Inference) : 학습된 f에 새로운 데이터를 넣어 어떤 클래스인지 예측
Classifier 를 위한 핵심 질문
Q1. 어떤 분류기를 쓸 것인가?
- 모델(Model) 선택의 문제 -> 어떤 형태의 함수 f을 사용할지 결정
Q2. 분류기가 얼마나 좋은가?
- 손실 함수 (Loss Function)의 문제 -> 분류기의 성능을 수치로 측정하는 방법
Q3. 최적의 분류기를 어떻게 찾는가?
- 최적화 방법 (Optimization Method)의 문제, 손실을 최소화하는 방향으로 모델을 업데이트 하는 방법 결정
Linear Classification
- 선형 분류는 어떤 모델을 쓸 것인가에 대한 답 :
- 직선(또는 초평면)으로 두 클래스를 나누겠다는 접근
- 두 클래스를 가르는 직선 : 결정 경계 (Decision boundary) -> 선형 모델
각 기호를 설명
- φ(x): 입력 x를 변환한 피처 벡터입니다. 예시에서는 φ(x) = [x₁, x₂]로 단순히 입력값 그대로를 씁니다.
- w: 가중치 벡터(weight vector)로, 분류기의 파라미터입니다. 이 w가 결정 경계의 방향과 기울기를 결정합니다. w = [w₁, w₂]는 결정 경계에 수직인 법선 벡터(normal vector)이기도 합니다.
- w · φ(x): 두 벡터의 내적(dot product)으로, 각 피처에 가중치를 곱해서 더한 값입니다. 이것이 바로 스코어(score)입니다.
- sign(z): 부호 함수로, z > 0이면 +1, z < 0이면 -1, z = 0이면 0을 반환합니다.
Perceptron (퍼셉트론)
- 선형 분류기의 구조 -> 신경망 다이어그램으로 그리기 : 각각 가중치와 곱해진 후 모두 더해지고, 그 결과에 활성화 함수가 적용
- 여기서 활성화 함수 sign 함수를 쓰면 : 퍼셉트론
- 현대 딥러닝 신경망의 기본 단위
Zero-One Loss : 분류기가 얼마나 좋은지에 대한 직관적인 방법 \(\operatorname{Loss}_{0\text{-}1}(x,y,\mathbf{w}) = \mathbf{1} \bigl[ f_{\mathbf{w}}(x) \neq y \bigr]\)
- 조건이 참이면 1, 거짓이면 0을 반환
-
훈련 데이터 전체에 대한 평균 손실인 TrainLoss는 단순히 전체 중 틀린 비율, 즉 오분류율
- 충분한가?
- 두 분류기의 같은 수의 점을 맞추더라도 하나는 경계가 데이터 점들에 아슬아슬하게 붙어있고, 다른 하나는 여유 있게 가운데를 지나갈 수 있음.
- 여유를 수치화 = 마진 (Margin)
Score : 분류기가 이 점을 양성으로 얼마나 확신하는지를 나타냄
Margin : 예측이 정답 방향과 얼마나 잘 일치하는지를 재기 위함.
- 마진을 사용한 공식
- 0 이하라면 손실1, 그 외엔 0
Hinge Loss
- Gradient Descent 의 목표 : TrainLoss(w)를 최소화하는 w를 찾는 것
- Zero-One Loss : 계단 함수의 미분이기에 거의 모든 곳에서 0
이 수식의 의미
- 마진 (w · φ(x))y가 1 이상이면 → max{1-마진, 0} = max{음수, 0} = 0. 완전히 안전하게 맞혔으면 손실 없음.
- 마진이 0~1 사이이면 → 0과 양수 사이, 즉 손실 있음. 맞히긴 했지만 확신이 부족하면 손실 부과.
- 마진이 0 이하이면 → 1-마진 > 1, 손실이 큼. 틀렸으면 손실 큼.
\[\nabla_{\mathbf{w}} \operatorname{Loss}_{\text{hinge}}(x,y,\mathbf{w}) = \begin{cases} -\boldsymbol{\phi}(x)\,y, & \text{if } 1-(\mathbf{w}\cdot\boldsymbol{\phi}(x))y > 0 \\[6pt] 0, & \text{otherwise} \end{cases}\]Hinge Loss : 마진이 작을수록 연속적으로 증가하는 기울기를 가진다.
- gradient descent가 작동
마진이 1보다 작을 때, gradient가 존재 하고 그 방향으로 w를 업데이트
Gradient Descent는 마진이 1보다 작은 경우에만 작동, 그 방향으로 W를 밀어 마진을 키운다.
Logistic Regression
비선형 분리 문제 (Non-Separable Case)
- 데이터가 직선 하나로만 완전히 분리되지 않는 경우
- 어떤 선형 경계를 써도 오분류가 발생
- Hinge Loss를 최소화해도 완벽한 분류는 불가능
확률적 결정 (Probabilistic Decision)
- hard decision에서 한 걸음 더 나아가면, 확률로 답하는 방식을 생각
- 결정 경계에서 멀리 떨어진 놈은 높은 확신도를 가지고 있다.
로지스틱 회귀(Logisitc Regression)
- 분류 문제를 회귀 모델로 푸는 방법
- 출력이 0 또는 1의 hard label이 아니라, 클래스에 속할 확률을 예측
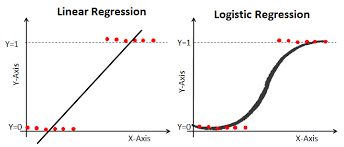
-
기존 퍼셉트론 구조 : 입력 피처에 가중치를 곱해 weighted sum을 계산 \(\sigma(z) = \frac{1}{1+e^{-z}}\)
- 시그모이드 함수의 성질
- z가 매우 크면 : 확실하게 클래스 1
- z = 0 : 0.5 반반
- z가 매우 작으면 : 확실하게 클래스 0
- 시그모이드 함수의 성질
Binary Cross-Entropy (BCE) Loss
- 로지스틱 회귀에서는 hard label이 아닌 확률을 출력 : 새로운 손실 함수가 필요
- 이진 교차 엔트로피가 필요
이 손실을 최소화 : 곧 훈련 데이터의 로그 가능도 (log-likelihood)를 최대화하는 것 \(\nabla_{\mathbf{w}} \operatorname{Loss}(x,y,\mathbf{w}) = (p-y)\boldsymbol{\phi}(x)\)
| 회귀 (Regression) | 분류 (Classification) | |
|---|---|---|
| 예측값 f(x) | 스코어 그 자체 | sign(스코어) |
| 타겟과의 관계 | 잔차 (score - y) | 마진 (score × y) |
| 손실 함수 | Squared loss, Absolute deviation | Zero-one, Hinge, Logistic |
| 최적화 알고리즘 | Gradient descent | Gradient descent |
Neural Networks
로지스틱 회귀까지는 단일 클래스 분류기
- 클래스가 여러 개면 어떻게 할까요?
다중 클래스 로지스틱 회귀
- 클래스마다 별도의 가중치 벡터를 정의
- 클래스 y에 대한 가중치 벡터를 정하고, 클래스의 점수가 가장 높은 클래스를 예측하는 값으로 선택
단층 퍼셉트론(Single-Layer Perceptron)
단층 신경망은 두 층으로 구성
- 입력층 (Input Layer) : 입력값을 그대로 담는 노드들. 계산을 수행하지 않는다.
- 출력층 (Output Layer) : 각 노드가 하나의 퍼셉트론. 실제 계산이 일어나는 곳
Softmax 활성화 함수
- 다중 클래스에서 각 출력 노드의 점수를 확률로 바꾸기 위함.
- 시그모이드를 각 노드에 독립적으로 적용하면 확률의 합이 1이 되지 않는다.
- 출력 벡터 전체에 한꺼번에 적용
왜 지수함수 eˣ를 쓰는가?
- 항상 양수이므로 확률로 쓸 수 있다.
퍼셉트론의 가중치를 적절히 설정 - 논리 함수를 표현할 수 있고, 반대로 학습은 적절한 가중치를 데이터로부터 자동으로 찾는 과정
한계점
- 퍼셉트론은 XOR을 못한다.
- 어떤 직선을 그어도 분리가 불가능한 조건 생김.
- 퍼셉트론은 선형 분류기 : 선형 분리 불가능한 문제는 해결할 수 없다.
Multi-Layer Perceptron (MLP)
- 단층에서 불가능한 XOR을 은닉층 하나를 추가해서 해결
새로운 구조 (2층 신경망):
- 입력층: x₀=1(bias), x₁, x₂
- 은닉층(Hidden Layer): h₀=1(bias), h₁, h₂
- 출력층: o₁
입력층과 은닉층 사이의 가중치: W1₀₁, W1₀₂, W1₁₁, W1₁₂, W1₂₁, W1₂₂
은닉층과 출력층 사이의 가중치: W2₀₁, W2₁₁, W2₂₁ \([w^{(2)}_{01},\, w^{(2)}_{11},\, w^{(2)}_{21}] = [1,\;1,\;-1.5]\)
\[o_1 = \operatorname{step} \left( h_1 + h_2 - 1.5 \right)\]2-Layered Feedforward Neural Network
- Hidden Layer (은닉층)
- 각 노드가 무엇을 표현해야 하는지는 데이터에 명시되어 있지 않음.
- 훈련이 끝난 후 보면, 어떤 노드는 수평선에 반응하고 어떤 노드는 곡선에 반응하는 등 자동으로 의미있는 특징을 학습한 것을 볼 수 있다.
분류가 아니라 연속적인 실수값을 예측하는 회귀 문제에서는 출력층이 달라진다.
-
Linear Neuron (선형 뉴런)
- 출력 노드의 활성화 함수 : 항등 함수 (identity function)
단층 퍼셉트론의 2가지 한계:
- 분류 문제 : 비선형 결정 경계를 만들 수 없다. (XOR 불가)
- 회귀 문제 : 비선형 함수를 근사할 수 없다.
Universal Approximation Theorem (보편 근사 정리)
\[|h_\varepsilon(x) - f(x)| < \varepsilon\]
- 어떤 연속 함수 f(x)가 있더라도, 은닉층이 1개인 신경망이 존재하여 다음을 만족한다.
- squashing 활성화 함수를 사용하고, 은닉 유닛이 충분히 많으면 된다.
네트워크를 더 깊게 만들기
2층이면 이론적으로 모든 함수를 근사할 수 있지만, 현실에서 더 깊은 네트워크를 쓰는 이유
- 1층 신경망
- φ(x): 입력 특징 벡터
- w : 가중치 벡터
- 입력에 가중치를 그냥 내적하면 끝.
- 2층 신경망 (은닉층 1개)
- V : 입력층 -> 은닉층 사이의 가중치 행렬
- σ: 활성화 함수
- w : 은닉층 -> 출력층 사이의 가중치 벡터
- 3층 신경망 (은닉층 2개)
- V1 : 입력층 -> 첫 번째 은닉층 가중치 행렬
- V2 : 첫 번째 은닉층 -> 두 번째 은닉층 가중치 행렬
- w : 두 번째 은닉층 -> 출력층 가중치 벡터
Shall vs Deep Network
같은 수의 가중치라면, 얕게 쌓는 것과 깊게 쌓는 것 중 어느 게 더 강력한가?
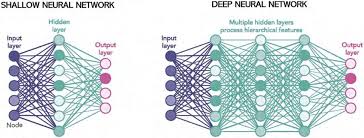
정답 : 깊은 네트워크 (Deep Network)가 훨씬 유리하다.
- 계산의 재사용 (Reusing Computations)
- 이전 층에서 계산한 결과를 다음 층의 여러 노드가 함께 사용
- 같은 파라미터로 더 많은 표현이 가능
- 추상화의 계층 (Hierarchy of Abstraction)
- 각 층이 이전 층의 출력을 입력으로 받아 점점 더 추상적인 개념을 학습
- 경험적 우월성
- 그렇다면 무엇이 가능하게 한 것일까?
Deep Neural Networks
층의 개수에 따라 결정 경계가 어떻게 달라지는가?
- 0개 은닉층 = 단층 퍼셉트론
- 완전히 선형
- 2차원 입력에서의 결정 경계는 직선 하나
- 1개 은닉층 추가
- 각 은닉 뉴런이 직선 하나를 만들고, 출력층에서 이 직선들을 조합
- 여러 직선의 교차 가능
- 볼록 영역 (convex region)의 경계 표현 가능
- 2개 은닉층
- 볼록 영역의 조합이 가능
- 결정 경계의 특징 : 비볼록(non-convex) 영역 표현 가능
- 예시 ) 도넛 모양, U자 모양 등의 형태 가능
깊이가 필요한 이유
1. 추상화의 다층 구조 (Multiple levels of abstraction)
- 각 층이 서로 다른 수준의 개념 학습 : 아래 층일수록 구체적
2. 계산의 다단계 재사용 (Multiple steps of computation with reusing)
- 이전 층의 결과를 다음 층이 재사용
3. 경험적으로 잘 작동함 (Empirically works well)
여기까지가 신경망의 구조, 그렇다면 어떻게 학습을 시키는가?
역전파 (Backpropagation)
가중치들을 어떻게 숫자를 잘 맞추는 값으로 설정할 수 있을까?
정답 : 경사 하강법 \(\theta_{t+1} = \theta_t - \alpha \nabla_{\theta} \operatorname{Loss}\)
-
θ: 모든 가중치를 통칭하는 기호
-
α: 학습률(learning rate), 한 번에 얼마나 크게 업데이트할지
-
∇θ Loss: Loss를 각 가중치로 편미분한 그래디언트 벡터
-
Overview
왜 역전파가 필요한가?
각 가중치를 아주 조금 바꿔보면서 Loss가 얼마나 변하는지를 측정하기에 현대 신경망의 파라미터가 너무 많다.
- 수백만 번의 순전파가 필요
\[Wₖ(t+1) = Wₖ(t) - η · ∇L(Wₖ)\]순전파 : 입력 x에서 최종 예측값까지 데이터가 앞으로 흘러가는 과정
-
Wₖ(t): 현재 t번째 반복(iteration)에서의 가중치 -
η(eta): 학습률(learning rate) — 얼마나 크게 업데이트할지 조절하는 값 -
∇L(Wₖ): 손실 L을 가중치 Wₖ로 편미분한 값, 즉 “이 가중치를 조금 바꾸면 손실이 얼마나 달라지는가”
업데이트는 각각 수행해야 함.
- 입력층에 가까운 가중치의 기울기를 구하는 것은 간접적으로만 영향을 준다.
- 따라서 효율적인 계산을 위해 역전파가 필요
예시)
- 출력층에 가장 가까운 W₃의 기울기 구하기
∂L/∂W₃ 를 구하려면 연쇄 법칙(Chain Rule)을 사용
∂L/∂ŷ = 2(ŷ - y): 손실함수L = (ŷ-y)²를 ŷ로 미분한 것∂ŷ/∂z₃ = g₃'(z₃): 출력층 활성화 함수의 도함수 (회귀면 항등함수니까 값은 1)∂z₃/∂W₃ = h₂: z₃ = W₃·h₂ 이므로 W₃로 미분하면 h₂가 남음
- W₂의 기울기 구하기
-
∂L/∂ŷ · ∂ŷ/∂z₃: 이미 W₃ 계산 때 구한 값! → 재사용 가능∂z₃/∂h₂ = W₃: z₃ = W₃·h₂ 이므로 h₂로 미분하면 W₃∂h₂/∂z₂ = g₂'(z₂): 두 번째 층 활성화 함수의 도함수∂z₂/∂W₂ = h₁: z₂ = W₂·h₁ 이므로 W₂로 미분하면 h₁
Backpropagation : Algorithm
Step 1. Forward pass (순전파)
- 훈련 데이터 (x, y) 중 x를 신경망에 입력
- 각 층에서 zₖ = Wₖ·hₖ₋₁ 계산
- hₖ = gₖ(zₖ) 계산
- 중간값(zₖ, hₖ)을 모두 저장
Step 2. Backward pass (역전파) : 출력층에서 입력층 방향으로 거꾸로 기울기를 계산
- 먼저
∂L/∂W₃를 계산 (출력층에서 가장 가까우니 쉬움) - 계산 과정에서 나온 중간 미분값들(예:
∂L/∂ŷ · ∂ŷ/∂z₃)을 저장 ∂L/∂W₂를 계산할 때 저장된 값을 재사용- 같은 방식으로
∂L/∂W₁까지 계속
Step 3. 전체 완성 \(∂L/∂W₁ = (∂L/∂ŷ · ∂ŷ/∂z₃ · ∂z₃/∂h₂ · ∂h₂/∂z₂ · ∂z₂/∂h₁) · (∂h₁/∂z₁) · (∂z₁/∂W₁)\)
- 모든 가중치 (W₁, W₂, W₃)에 대한 기울기를 이렇게 역방향으로 차례로 계산하고 난 이후, 경사 하강법으로 모든 가중치를 동시에 업데이트 가능
Backpropagation Summary
-
기울기를 효율적으로 계산하는 방법 : 모든 가중치에 대해 기울기를 하나하나 따로 계산하기에는 엄청난 비용이 들기 때문에, 한 번의 역방향으로 모든 기울기를 동시에 구하기가 가능
- 연쇄 법칙을 적용하되 중간 계산을 재사용 : 출력층에서 입력층 방향으로 기울기를 전파하면서, 이미 계산한 값을 버리지 않고 저장해 다음 단계에 재활용
- 깊은 신경망에서도 잘 작동
활성화 함수 (Activation Function)
활성화 함수가 없으면 어떻게 되는가?
- 깊은 신경망에서 활성화 함수를 모두 없앤다면?
- 몇 층을 쌓더라도 결국 단순한 선형 변환 하나로 붕괴
- 활성화 함수는 신경망에 비선형성(Non-linearity)를 추가
역전파와 활성화 함수의 연결 \(∂L/∂W₁ = (∂L/∂ŷ) · (∂ŷ/∂z₃) · (∂z₃/∂h₂) · (∂h₂/∂z₂) · (∂z₂/∂h₁) · (∂h₁/∂z₁) · (∂z₁/∂W₁)\)
∂hₖ/∂zₖ = gₖ'(zₖ): 활성화 함수의 도함수- 역전파 경로에 활성화 함수의 도함수가 곱해지는 구조
Example 1) Step Function (계단 함수) \(h = g(z) = \begin{cases} 1, & z \ge 0 \\ 0, & z < 0 \end{cases}\) 도함수 : z = 0 인 지점을 제외한 모든 곳에서 도함수 = 0
- 역전파 공식에서 중간에 0이 곱해지면 전체 기울기가 0이 된다.
Example 2) Sigmoid Function (시그모이드 함수) \(\sigma'(z) = \sigma(z) \bigl(1-\sigma(z)\bigr)\) 이 도함수의 최댓값은 z = 0 일 때, 0.5 x 0.5 = 0.25
- 도함수 값이 항상 0.25이다.
- z가 크거나 작은 극단값일 때는 도함수가 거의 0에 수렴
- 층이 깊어질수록 초기 층의 가중치는 사실상 업데이트 X (Vanishing Gradient)
기울기 소실 (Vanishing Gradient)
- 이상적인 역전파 : 출력층에서 입력층까지 기울기가 충분히 전달
- 기울기 소실 현상 : 출력층 근처 기울기가 크지만, 입력층으로 갈수록 기울기가 거의 0이 되는 현상
그렇다면 바람직한 Activation Function은 무엇인가?
조건 1. 비선형 (Non-linear)
조건 2. 거의 모든 곳에서 미분이 가능 (Differentiable almost everywhere)
조건 3. 기울기가 소실되지 않음. (Non-vanishing)
조건 4. 실제 뉴런과 유사 (옵션)
- 가중합이 충분히 클 때만 신호를 발화하는 특성
- 선택 조건 : 반드시 필요하지는 않지만 있으면 좋은 성질
ReLU (Rectified Linear Unit)
\[h = g(z) = \max(0, z)\]2006년까지의 기울기 소실이 해결되지 않았을 때, ReLU의 등장으로 해결
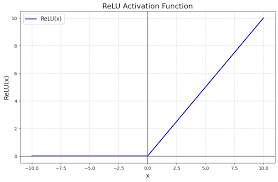
z > 0: 그대로 통과 (h = z)z <= 0: 차단 (h = 0)
ReLU 함수의 도함수 \(g'(z) = \begin{cases} 1, & z > 0 \\ 0, & z \le 0 \end{cases}\)
Convolutional Neural Network
합성곱 신경망 (Convolutional Neural Network, CNN)
- MLP의 각 층은 완전 연결 (Fully-connected)구조
다른 종류의 신경 층에는 어떤 것이 있을까?
Deep Q-Network(DQN)
- MLP로 이미지 처리와 같은 상태 공간이 큰 걸 하려고 하면 파라미터 수가 기하급수적으로 증가
CNN Motivation
- CNN은 이미지에 적합
- 유용한 이미지 특징은 국소적 (local)
- Atari 게임에서 이미지의 작은 패치만 봐도 구분이 가능할 때, 화면 전체를 볼 필요가 없다.
예시 ) 공간 필터 (Spaial Filter)
- Horizontal Sobel : 수평 방향의 경계 강조 가능 (도로의 차선처럼 가로 방향 에지 확인)
- Vertical Sobel : 수직 방향의 경계 검출
요약
MLP의 한계 정리
- MLP(완전 연결층)는 강력하지만 고차원 데이터(이미지 등)에서 파라미터 수가 폭발적으로 늘어 비효율적
CNN의 해결책
- 합성곱 층은 유용한 특징이 인접 픽셀에서 나온다는 가정을 통해 작은 필터로 이미지 전체를 효율적으로 처리
앞으로의 신경망
- RNN (순환 신경망) : 시계열, 텍스트, 음성처럼 순서가 있는 데이터에 적합
- Transformer : 문장에서 멀리 떨어진 단어 사이의 관계처럼 장거리 의존성을 모델링 (GPT, BERT 등 현재의 대형 언어 모델(LLM)의 기반 구조)