Data Science 3.Classification
이번 포스트는 Classification과 LM, SVM에 대해 다룬다.
Classification
Classification (분류)가 무엇일까?
-
어떤 데이터 객체를 미리 정해진 클래스(label) 중 하나에 배정하는 작업 \(f(x) \rightarrow y\)
- x : 입력 데이터
- y : 예측할 라벨
- f : 분류 모델 (classifier)
-
예시)
- 환자 정보 -> positive / negative
- 이메일 -> spam / not spam
- 뉴스 기사 -> sports / politics / weather
-
중요한 부분 : 클래스(label)가 미리 정의되어 있다.
classification vs supervised Learning
- classification 모델은 labeled data로 학습을 진행
- 정답이 붙어 있는 데이터를 활용하기에 대표적인 supervised learning (지도 학습)이다.
왜 Classification이 중요한가?
- 데이터를 그냥 쌓아두는 것은 의미가 없다.
- classification을 통해 data를 decision에 쓸 수 있는 intelligence로 바꾼다.
- 대표적 예시
- Fraud Detection : 새 거래가 들어올 때 거래가 정상인지 사기인지 구분
- Recommender Systems : 사용자가 이 상품을 좋아할까?
- Medical Diagnosis : 환자가 들어올 때 어떤 질병 범주에 속하는가
- Network Analysis : 네트워크 상태가 정상인가 이상인가
Decision Tree
Decision Tree란?
- 데이터를 기반으로 트리 구조를 만들어서 분류하는 모델
- class-labeled training data 사용
- tree 구조
- Internal node : 어떤 속성(attribute)을 기준으로 분기
- Leaf node : 최종 클래스(label)
- 표현력
- 어떤 함수도 표현이 가능하다. (강력)
- non-linear decision boundary도 가능
- 복잡한 데이터 구조도 잘 표현이 가능
Decision Tree의 목표 : Optimal Tree
- Compact : 트리는 가능한 작아야 한다.
- Consistent : training data를 완벽히 맞춰야 한다.
- Pure leaf nodes : leaf node 안에 있는 데이터는 모두 같은 클래스
작으면서도 완벽한 트리를 만들 수 있는가?
- 불가능 (NP-complete)
- 모든 가능한 트리를 다 비교해야 한다.
- 시간이 너무 오래 소요된다.
- Greedy Approach
- 아이디어 : 매 단계에서 가장 좋은 선택만 한다.
- 모든 데이터를 root에 넣음
- 가장 좋은 attribute를 선택해서 split
- 각 노드에서 반복
- 모든 leaf가 pure해질 때까지 반복
- 아이디어 : 매 단계에서 가장 좋은 선택만 한다.
Best attribute를 구하는 방법
-
좋은 split의 기준 : 데이터를 더 깔끔하게 나누는 방법
-
uncertainty를 많이 줄이는 attribute
- uncertainty를 측정하는 방법
Entropy
개념 : 데이터가 얼마나 섞여 있는가?
-
Entropy가 크다 = 클래스가 많이 섞여 있다. = 불확실성이 크다.
-
Entropy가 작다 = 클래스가 거의 한쪽이다. = 불확실성이 작다. \(E(D) = - \sum_{k=1}^{c} p_k \log_2 p_k\)
- D : 현재 데이터 집합
- c : 클래스 개수
- Pk : 클래스 k가 나올 확률
- 앞에 마이너스(-)가 붙은 이유 : 로그 안에 값이 1보다 작아서 음수로 나와 결과를 양수로 만들기 위함
각 클래스 비율을 이용해서 그 데이터가 얼마나 뒤섞여 있는지 계산
IG (Information Gain)
-
속성을 기준으로 split할 때 얼마나 Entropy가 줄어드는가 \(Gain(A) = E(D) - E_A(D)\)
E(D): 나누기 전 전체 데이터 entropyEa(D): attribute A로 나눈 뒤의 평균 entropy
-
해석
- Gain이 크다.
- 나누고 나서 훨씬 덜 헷갈린다.
- 좋은 속성
- Gain이 작다.
- 나눠도 여전히 섞여 있다.
- 별로인 속성
- Gain이 크다.
-
전체 데이터에서 한 번만 attribute를 고르는게 아니라, 각 branch마다 따로 best attribute를 다시 고른다.
- Decision Tree는 branch마다 다른 attribute를 선택 가능
- Final Decision Tree : 모든 leaf가 Pure
-
Information Gain의 한계
- 얼마나 Pure한지 나눠지는지만 신경쓴다.
- 너무 많은 가지로 쪼개지는 문제는 잘 고려하지 않는다.
- Ex) 학번 입장으로 나누면 다 나눠지기는 함.
- 실제로는 안 좋은 split
- 보완할 방법
- Gain Ratio : 데이터를 얼마나 잘 쪼개는가
OverFitting
개념 : 트리가 너무 커지고 복잡해지면 훈련 데이터의 작은 noise나 예외까지 전부 외워버리는 현상
- Training Accuracy는 계속 올라감
- 더 많은 분할로 훈련 데이터를 더 잘 맞출 수 있다.
- Test Accuracy는 어느 순간부터 떨어짐
트리가 너무 작으면 데이터 구조를 충분히 못 배움 = Underfitting 문제
대표적 방법 : compact tree
- max depth 제한 : 너무 깊으면 과적합 위험
- minimum samples per leaf 설정 : 데이터가 너무 적으면 stop
- pruning (가지치기) : Gain이 너무 적으면 stop
Pre-Pruning : 트리를 다 만들기 전에, “적당히” 멈춰서 과적합 방지
- useful할 때만 split
- 어떤 node를 나눌 때 정보가 별로 안 늘어나면 굳이 split을 안 함
- 그냥 majority label로 끝냄
- 굳이 더 쪼개지 말고 그냥 +로 결정
Post-Pruning : 일단 트리를 다 끝까지 만들고 난 이후에, 필요 없는 가지를 잘라낸다.
- 트리가 커서 복잡함 -> 일부 가지를 제거하여 더 단순한 구조로 표현
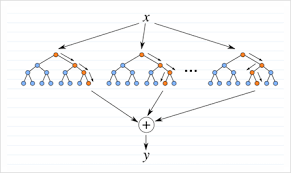
Random Forest
Decision Tree의 진화
- 여러 개의 Decision Tree를 합쳐서 더 좋은 모델을 만든다.
- Data Sampling (Bagging) : 원본 데이터에서 랜덤하게 여러 개의 dataset 생성 (중복을 허용하는 sampling)
- Attribute Sampling : 매 split 마다 전체 feature가 아니라 일부만 사용
- 트리들이 서로 다르게 만들어지도록 함.
- 전체 과정
- 데이터를 여러 개 샘플링
- 각각 Decision Tree 생성
- 각 Tree가 예측을 수행
- 투표 (majority voting)
Naive Bayesian Classifier
Naive Bayes Classifier란?
- 확률로 클래스를 결정하는 매우 빠른 분류기
- binary/multi-class가 다 가능
- 학습이 매우 빠르다.
- 데이터가 적어도 된다.
- 핵심 공식
| 기호 | 의미 |
|---|---|
| P(A|B) | B를 봤을 때 A일 확률 (우리가 구하려는 것) |
| P(B|A) | A일 때 B가 나올 확률 |
| P(A) | A 자체 확률 (prior) |
| P(B) | B 전체 확률 |
- 데이터 x가 주어졌을 때, 어떤 class일 확률이 더 큰지 비교하기
Histogram : 부드러운 곡선 (distribution) : 확률 밀도 함수 느낌
- 각 클래스마다 “확률 분포”를 만든다.
- x가 주어질 때 class y일 확률
- 확률을 비교해서 더 큰 쪽을 선택
Navie Bayes 작동 방식
- 클래스별 분포 학습
- 새로운 데이터
x들어옴 P(y | x)계산- 가장 큰 확률 계산
-
Multiple Features 인 경우 \(P(x|y) = P(x_1, x_2, ..., x_n | y)\)
- Naive를 가정
- feature들이 서로 독립적이라고 가정을 한다.
-
최종 공식 \(P(y|x) \propto P(y) \cdot \prod_{j=1}^{n} P(x_j | y)\)
- 각 feature가 이 클래스에 얼마나 잘 맞는지 전부 곱해서 판단
Naive Bayes의 장점
1. 빠르다.
- 한 번 데이터를 스캔하면 모든 확률 계산이 가능하다.
- 각 feature별 빈도만 세면 된다.
- 모델 자체가 확률 테이블
2. Irrelevant feature에 강하다
- Irrelevant feature 같은 경우는 값이 거의 비슷하다.
- 결과에 영향이 거의 없음.
3. Multi-class가 가능
- class의 개수에 제한이 없다.
- 전부 계산하여서 Max 값 선택이 끝
Linear Classifier
Linear Classification이란?
-
선형 분류 : 입력 feature들의 선형 결합(linear combination)으로 클래스를 예측하는 방법 \(y = \sigma(w^T x + b)\)
- x : 입력 feature 벡터
- w : 각 feature의 중요도 (가중치)
- b : bias
sigma: 최종적으로 label을 정하는 함수
-
직관적 해석
- 각 feature에 가중치를 곱해서 더한 점수(score)를 만든다.
-
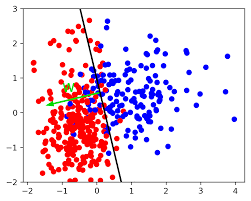
Geometric Interpretation \(w^T x + b = 0\)
- 결정경계
- 2차원 : line
- 3차원 : 평면
- 더 높은 차원 : 초평면
- 경계가 데이터를 둘로 가르는 기준선 역할
- 결정경계
왜 Linear Classification 이 중요한가?
- Interpretability
- 각 feature의 영향이 직접 드러난다.
- 어떤 feature가 결과에 얼마나 영향을 줬는지 설명하기가 쉽다.
- Generalizability
- 복잡도가 낮아서 너무 훈련데이터에 과하게 맞춰질 가능성이 낮다.
- Performance
- feature engineering을 잘하면 강력한 성능을 가진다.
- Efficiency & Scalability
- 학습이 빠르다
- 예측이 빠르다.
- 큰 데이터셋에도 잘 버틴다.
Linear Regression
-
선형 회귀(Linear Regression) : 입력 feature를 바탕으로 연속값(continuous value)을 예측하는 모델 \(y = w^T x + b\)
- 회귀 : feature들의 선형 결합으로 타겟값을 가장 잘 설명하는 직선이나 평면을 찾는 것
-
Linear Classification과의 공통점
- 둘 다 기본 형태는
w^T x + b를 쓴다.
- 둘 다 기본 형태는
-
차이점
- 회귀 : 출력을 실제 숫자값으로 본다.
- 분류 : 출력을 label 결정용 score로 본다.
w를 구하는 방법
- 목표 : 좋은 직선/평면을 찾기 위해서는 가중치 w와 bias b를 학습해야 한다.
- 예측이 실제값과 최대한 비슷해지도록 w를 조정
-
Training Dataset \((x_i, y_i)\)
- x : 입력 벡터
- y : 실제 정답값
-
Prediction \(\hat{y}_i = w^T x_i + b\)
-
Loss Function \(L(\hat{y}_i, y_i)=\frac{1}{2}(y_i-\hat{y}_i)^2\)
- leasat squared loss
제곱하는 이유
- 오차가 더 크면 더 큰 벌점을 주기 위해
- 음수/양수 오차를 모두 양수로 만들기 위해
Cost Function : 전체 데이터셋에 대한 총 손실 \(J(w)=\sum_{i=1}^{n} L(\hat{y}_i, y_i)\)
- 모든 데이터 포인트에서의 오차를 다 더한 값
- 좋은 w는 전체 예측오차인 Cost Function값을 작게 만드는 w
Gradient Descent (GD)
Cost Function J(w)를 어떻게 최소화해야할까?
\(w \leftarrow w - \eta \nabla J(w)\)
- 현재 위치에서 기울기(gradient)를 보고 가장 가파르게 내려가는 방향으로 이동한다.
- Small Learning Rate : 너무 조금씩 움직여서 느리다.
- Proper LR : 적절한 속도로 최소값 도달
- Large LR : 튕김 -> 발산
Gradient Descent (Batch GD)
- 전체 데이터를 다 보고 gradient 계산
- 안정적이고 방향이 정확함
- 느리다.
Stochastic Gradient Descent (SGD)
- 데이터를 하나씩 보고 업데이트
- 빠르다, 불안정하다 (노이즈 존재)
Linear Classification
Regression -> Classification 연결 \(\hat{y} = w^T x + b\)
-
이 값을 score, confidence로 해석
-
분류 (class label)로 바꾸는 방법
- sign 사용 (Perceptron)
Perceptron
-
가장 단순한 선형 분류기 \(\hat{y} = sign(w^T x + b)\)
-
Loss Function \(L(w) = \max(0, -y(w^T x + b))\)
- 맞게 분류 :
loss = 0 - 틀림 :
loss > 0
- 맞게 분류 :
-
-
틀린 데이터만 패널티를 준다.
-
한계점
- confidence 고려 X
- barely correct 와 매우 확신 correct를 구분 못함
- 불안정 : noise 에 민감
- hard decision : 확률이 존재 X
- confidence 고려 X
Logistic Regression
선형 score를 확률로 바꾼다. (Perceptron의 업그레이드 버전)
-
Sigmoid 함수 \(\sigma(z) = \frac{1}{1 + e^{-z}}, \quad z = w^T x + b\)
- 출력을
0 ~ 1사이로 변환
- 클래스 1
- 그 외는 class 0
- 출력을
-
Loss : Cross Entropy \(L(w) = -\sum (y \log \hat{y} + (1-y)\log(1-\hat{y}))\)
- 맞게 예측 + 확신이 높으면 Loss가 작다.
- 틀림 + 확신이 높으면 Loss가 매우 크다.
틀렸는데 확신까지 높은 경우 강하게 패널티
Cross Entropy 식 해석
-
\[y log(ŷ) + (1-y) log(1-ŷ)\]
- y = 1일 때 :
log(y^) - y = 0일 때 :
log(1 -y)
- y = 1일 때 :
- 확률 기반 학습을 가능하게 한다.
Support Vector Machine (SVM)
SVM의 등장 배경
-
Linear model -> Decision Boundary (직선/평면) 여러 개가 가능
-
가장 좋은 선 찾기 : Decision Boundary 기준
- 데이터를 잘 맞추고 (training accuracy)
- 새로운 데이터에도 잘 맞아야 함 (generalization)
-
핵심 아이디어 : Margin 최대화
-
Margin = Decision Boundary와 가장 가까운 데이터까지의 거리
- 가장 margin이 큰 boundary를 선택
- margin이 클수록 noise에 덜 민감하고 일반화가 잘 된다.
-
Support Vector
Decision Boundary를 결정하는 가장 가까운 점들
- 모든 데이터가 아니라 딱 몇 개의 점만 중요하다.
이름이 support인 이유
- 이 점들이 boundary를 지지 (support)하기 때문에
-
Margin 수식 \(\text{margin} = \frac{2}{||w||}\)
- Decision Boundary
- 양쪽 경계
- 이 두 개 사이의 거리 = margin
-
거리 공식 사용 \(\frac{|w^T x + b|}{||w||}\)
SVM의 목표 함수 \(\max_{w,b} \frac{1}{||w||}\)
- margin 최대화
||w||최소화
-
Constraints (제약 조건) \(y_i (w^T x_i + b) \ge 1\)
- 모든 데이터가 margin 밖에 있어야 한다.
-
전체 최적화 문제 \(min ||w||^2\)
\[subject to y_i(w^T x_i + b) ≥ 1\]- Margin 최대화
- 모든 데이터 올바르게 분류
Lagrange Multiplier
Constraint 있는 문제에서는 그냥 경사하강법 사용 X
해결 방법 : constraint를 식 안으로 넣는다. \(L(w, \lambda) = \text{objective} + \lambda \times \text{constraint}\)
- 조건을 어기면 penalty를 주는 방식
SVM의 최적화 문제 \(\max_{w,b} \frac{1}{\|w\|} \quad \text{s.t. } y_i(w^Tx_i+b)\ge 1,\ \forall i\)
-
||w||를 작게 만들어 margin을 크게 하고 -
동시에 모든 데이터가 아래의 식을 만족 \(y_i(w^Tx_i+b)\ge 1\)
Lagrangian form 형태 만들기 \(\mathcal{L}(w,b,\alpha) = \frac12 w^Tw - \sum_{i=1}^n \alpha_i \big(y_i(w^Tx_i+b)-1\big), \quad \alpha_i \ge 0\)
-
\alpha_i: 아래의 조건을 얼마나 강하게 반영할지 나타내는 계수 \(y_i(w^Tx_i+b)\ge 1\) -
Stationary Condition \(\frac{\partial \mathcal{L}}{\partial w} = w-\sum_{i=1}^n \alpha_i y_i x_i = 0\)
\[w = \sum_{i=1}^n \alpha_i y_i x_i\]- 최적의 weight vector w는 그냥 독립적으로 생기는 것이 아니라,
- 학습 데이터들의 선형 결합으로 만들어진다.
- 양 클래스 (+1, -1)가 균형있게 형성에 참여해야 한다.
- 한쪽 클래스만 가지고 경계를 정하면 안되고,
- 양쪽에서 경계를 밀고 당기며 결정된다.
Dual Problem
- 계산 구조가 더 좋아진다.
- SVM의 Inner product 형태만 남으면 나중에 kernel trick과 연결 가능
- 어떤 점이 더 중요한지 잘 드러난다.
Prime : boundary (w,b) 직접 찾기
Dual : 각 데이터의 중요도 알파를 찾기
Interpretation of SVM
Support Vector
- 많은 알파 값은 0이 된다.
- 해당 점이 0이면 Decision Boundary에 기여 X
- 0보다 크면 그 점이 Support Vector
- SVM은 기본적으로 경계와 멀리 떨어진 점들은 신경을 쓰지 않는다.
- 경계에 가까운 점
- 잘못 분류될 위험이 있는 점이 중요
- 최적의 w : support vector들의 선형 결합으로 표현 가능
새로운 점 분류하기 \(f(x)=w^Tx+b = \sum_{i\in SV}\alpha_i y_i x_i^T x + b\)
- 새 점이 support vector들과 얼마나 유사한지를 보고 클래스를 결정
Limitation of Linear SVM
만약 데이터를 직선/평면 하나로 못 나눈다면?
-> 실제 데이터는 대부분 non-linearly separable
-
해결 방법 : Higher-Dimensional Mapping
- 원래 공간에서는 비선형 문제라면 한 차원을 높여 선형 문제로 만든다.
- 새 공간에서
- 를 통해 선형 SVM 적용
-
어떤 방식으로 매핑할까?
- 임의로 차원을 늘리기 X : 좋은 변환 함수가 필요
- 변환된 feature 계산 비용
- 고차원에서 최적화 비용이 크다.
Kernel Trick
\[f(x)=\sum \alpha_i y_i x_i^T x + b\] \[x_i^T x_j\]- 사실 상 φ(x) 자체는 필요 없음
Kernel Trick \(K(x_i, x_j) = \phi(x_i)^T \phi(x_j)\)
- 고차원으로 실제로 보내지 말고 내적 값만 직접 계산하자
전체 프로세스
- Linear SVM dual form 시작
-
Kernel 정의 : \(K(x_i,x_j)\)
-
Inner Product 교체
- 그대로 학습
Kernel 종류
1. Polynomial Kernel \(K(x_i,x_j) = (x_i^T x_j + c)^d\)
- feature 간 Interaction 반영
2. RBF (Gaussian) Kernel \(K(x_i,x_j) = \exp(-\gamma ||x_i - x_j||^2)\)
- 거리 기반 유사도
- 가까우면 값이 크고, 멀면 값이 작다.
Soft Margin SVM
- Hard Margin의 문제
- 모든 점이 완벽하게 분리되어 있어야 한다.
- 현실 데이터는 노이즈가 많고, outlier가 존재
- Infeasible 할 수 있다.
Slack Variable : 얼마나 margin을 위배했는가 \(\xi_i\)
- 값이 0 : 정상
- 0 ~ 1 : margin 안쪽
- 1보다 크다 : 잘못 분류
- 두 가지의 균형이 존재
- margin을 크게 (첫 항)
- error를 줄이기 (두 번째 항)
Hinge Loss
- Constraints 를 Loss로 변환
- Hinge Loss
- 잘 분류 + margin이 충분하다.
- 맞았지만 Margin이 작다. (Loss가 있음)
- 틀렸다. (Loss가 크다)
최종 목적 함수 \(\min \frac12||w||^2 + C \sum \max(0,1-y_i(w^Tx_i+b))\)