Data Science 5.Clustering
이번 포스트는 Clustering (군집화) 대해 다룬다.
Clustering
Introduction
-
Cluster가 무엇일까?
- 아무 점 모음 X
- 같은 cluster 안에서는 서로 비슷해야 함.
- 다른 cluster에 있는 점들과는 달라야 함.
내부적으로는 뭉쳐 있고, 외부와는 잘 구분되어야 함.
-
Clustering 이란 무엇일까?
- 주어진 데이터 포인트들을 k개의 그룹으로 나누는 것
- 입력 : 데이터 집합
- 출력 :
- 각 점이 어느 군집에 속하는지
- 각 군집의 중심 또는 대표 구조
- Unsupervised Learning (비지도 학습)
- 정답 Label이 없다.
- 데이터만 보고 알아서 구조를 찾아야 한다.
- 좋은 Cluster란 무엇인가?
- High intra-cluster similarity
- 같은 cluster 안에 있는 점들끼리는 가까워야 한다.
- Low inter-cluster similarity
- 군집과 군집 사이에는 차이가 커야 한다.
- Objective Function
- 거리 기반 : 점들이 가까우면 같은 군집
- 확률 기반 : 같은 분포에서 생성된 점이면 같은 군집
- density 기반 : 조밀한 덩어리를 하나의 군집으로 봄
- connectivity 기반 : 연결 구조가 비슷하면 같은 군집
- High intra-cluster similarity
- Clustering이 어디에 쓰이는가? (Application)
- Data Summarization : cluster center를 대표값으로 사용
- Image Color Reduction / Image Segmentation :
- K가 커질수록 표현력이 좋아지고 압축 효과는 줄어든다.
- 픽셀끼리 비슷한 색끼리 묶어, 이미지를 더 적은 색으로 압축하거나 영역별로 분할 가능
Centroid-based Clustering
K-Means Algorithm
각 군집을 대표하는 중심(Centroid) 기준으로 클러스터링 하는 방법
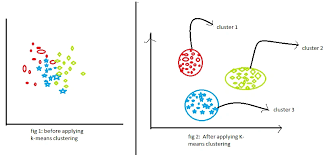
-
모든 데이터는 가장 가까운 중심에 할당된다.
-
K-means의 Objective Function
- within-cluster distance 최소화
- 자기가 속한 cluster 중심까지 거리만 더함.
-
중심 (centroid) 정의 \(\mu_\alpha = \frac{\sum [z_i]_\alpha x_i}{\sum [z_i]_\alpha}\)
왜 어려운가?
-
non-convex, non-continuous
- 최적해를 찾기 어렵다
-
Brute-Force 방법 (only 이론)
- 모든 cluster 조합을 다 만들어보고
- 각각 점수를 다 계산하여
- 최소를 선택
현실적으로 불가능 (Polynomial Time에 해결 X)
-
근사 알고리즘 사용
Step 1. Assignment Step
-
각 점을 가장 가까운 중심에 할당
-
중심을 랜덤으로 선택 (결과에 엄청 영향을 준다.) \(\alpha = \arg\min_\alpha ||x_i - \mu_\alpha||^2\)
-
각 데이터는 가장 가까운 중심으로 이동
-
Membership 표현
-
Step 2. Refit Step
-
각 cluster 중심을 다시 평균으로 계산 \(\mu_\alpha = \frac{\sum [z_i]_\alpha x_i}{\sum [z_i]_\alpha}\)
- Cluster 중심 = 평균
- 중심이 클러스터 내부로 이동 (더 중앙으로 가게 됨)
Step 3. 위 과정을 반복 (Convergence)
- 언제 멈추냐
- 중심이 더 이상 안 바뀔 때까지
K-means의 한계
- 구형 (Spherical) 가정
- K-means는 거리 기반이라 동그란 cluster를 잘 잡는다.
- 문제점 : 타원형, 길쭉한, 밀도 다른 cluster는 못잡음
- feature scale
- 스케일 큰 feature가 지배
- Outlier에 매우 민감
- 이상치 하나가 중심을 바꿔버린다.
-
경계에 있는 점 표현하기가 어렵고, overlap 표현 불가
- K를 미리 알아야 함.
- 현실에서는 모른다.
K-Medoids Algorithm
K-means와의 차이로 공부
핵심 아이디어
- cluster 중심이 “평균”이 아니라 실제 데이터 포인트
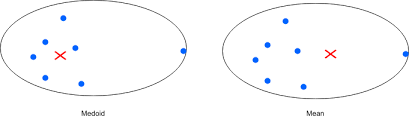
- Medoid
- cluster 안에서 다른 점들과의 총 거리가 가장 작은 실제 데이터
-
Objective Function \(\min \sum_{k=1}^{K} \sum_{x_i \in C_k} d(x_i, m_k)\)
- 전체 거리 최소화
PAM (Partitioning Around Medoids) Algorithm
- 초기화
- k개의 데이터 포인트를 medoid로 선택
- Assignment 단계
- 각 점을 가장 가까운 medoid에 할당
- Update
- cluster 안에서 총 거리 최소가 되는 새로운 medoid로 선택
- 반복
- medoid 바꿔가면서 전체 거리 줄어드는지 확인
Choosing the Number of Cluster K
K-means는 잘 작동하는 알고리즘이지만, k를 미리 알아야 한다는 가장 큰 문제 존재
- 데이터가 몇 개의 군집으로 나뉘는지 사전에 미리 알기 어렵다.
- 그냥 많이 나누는 것이 아닌 의미 있게 나누는 적절한 군집 수 필요
단순히 K가 커지면.?
- error가 줄어든다.
- 각 점이 자기 cluster 중심에 최대한 가깝게 가도록 만들기
Objective 값이 작다고 해서 무조건 좋은 clustering은 아니다.
Elbow Method
- k를 늘리면 error는 줄어들지만, 어느 순간부터 줄어드는 폭이 확 작아진다.
- 그 지점이 최적의 K 값
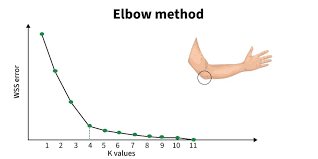
과정
k = 1,2,3,4,...이렇게 바꿔가면서 K-means를 여러 번 돌림- 각 K에 대해 objective value를 계산함
- 그래프로 그리고 감소가 급격하다가 완만해지는 지점 선택
- 장점 : 계산이 비교적 쉽고, 직관적이고, 많이 사용
- 단점 : elbow가 애매하거나, 그래프가 꺾이는 지점이 명확하지 않아서 사람의 주관이 들어감.
Silhouette Score
좋은 cluster
- cluster 내부는 잘 뭉쳐 있어야 하고, 다른 cluster와는 잘 떨어져 있어야 함.
각 점에 대한 점수 계산 \(a(i)=\frac{1}{|C_i|-1}\sum_{x_j \in C_i, j\neq i} d(x_i,x_j)\)
a(i): cohesion Score- 자기 군집 내부 평균 거리 : 작을 수록 좋다, 군집에 잘 어울린다는 뜻
b(i): Separation Score- 다른 군집과 얼마나 떨어져 있는가
- 자기 cluster가 아닌 다른 cluster들 중에서
- 가장 가까운 다른 cluster와의 평균 거리
- 다른 군집과 얼마나 떨어져 있는가
Sihouette Score 공식 \(s(i)=\frac{b(i)-a(i)}{\max(a(i),b(i))}\)
b(i)가 크고a(i)가 작아야 점수가 커진다.- 값 해석
s(i) = 1: 매우 좋다.s(i) = 0: 애매하다.s(i) < 0: 오히려 다른 cluster에 가까운 점이다.- 잘못 배정됐을 가능성이 크다.
최종 cluster quality \(S=\frac{1}{n}\sum_{i=1}^{n}s(i)\)
- 전체 데이터의 실루엣 평균을 구해서 그 clustering 전체의 품질 평가
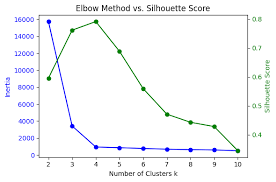
Elbow Method vs Silhouette Score 비교
Probabilistic Clustering
K-means / K-medoids의 한계
- 구 모양 (spherical) 가정
- 현실 데이터는 둥근 cluster 가정이 아니기에 못 잡음
- 경계에 있는 데이터는 애매함
GMM (Gaussain Mixture Model)
- 타원형 cluster 표현 가능
- covariance (분산 + 방향) 사용
- 기울어진 cluster 표현 가능
- cluster마다 다른 퍼짐
- 어떤 cluster는 넓고, 좁고 표현 가능
- 확률 기반 할당 : 더 현실적인 모델링
핵심 아이디어
- 데이터는 여러 개의 Gaussian (정규분포)의 섞임으로 만들어진다.
- probabilistic (확률 기반)
- generative (데이터 생성 모델)
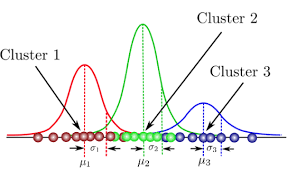
- Soft Clustering
x -> cluster 1 (70%)x -> cluster 2 (30%)
수식 : 각 cluster를 Gaussian (정규분포)로 본다. \(x_i \sim \mathcal{N}(\mu_\alpha, \Sigma_\alpha)\)
- mean : cluster 중심
- Covariance : cluster 모양 결정
- 작은 covariance : 뭉쳐 있다.
- 큰 covariance : 퍼져 있다.
- correlated : 상관 있다. 기울어진 타원
Dataset = Gaussians의 혼합물 \(p(x) = \sum_{\alpha=1}^{k} \pi_\alpha \mathcal{N}(x | \mu_\alpha, \Sigma_\alpha)\)
- mixing coefficient : 각 cluster의 비율 \(\sum \pi_\alpha = 1\)
Step 1. cluster 선택
Step 2. 해당 Gaussian에서 샘플링
Cluster Membership Assignment \(p(c_\alpha | x_i) = \frac{p(x_i | \mu_\alpha, \Sigma_\alpha)\pi_\alpha} {\sum_l p(x_i | \mu_l, \Sigma_l)\pi_l}\)
- 이 점이 cluster a 일 확률
- 분자 : 그 cluster일 likelihood x 그 cluster 비율
- 분모 : 전체 확률 (normalization)
- Goal : 데이터를 가장 잘 설명하는 Gaussian들을 찾기
EM Algorithm (Expectation-Maximization)
GMM의 파라미터를 어떻게 구할까?
전체 알고리즘 흐름
- 초기화
- E-step (확률 계산)
- M-step (파라미터 업데이트)
- 반복 (convergence까지)
E-Step (Expectation Step) \([z_i]_\alpha = p(c_\alpha | x_i) = \frac{p(x_i|\mu_\alpha,\Sigma_\alpha)\pi_\alpha}{\sum_l p(x_i|\mu_l,\Sigma_l)\pi_l}\)
- 이 데이터가 클러스터 a일 확률
- 가까운 cluster이면 확률이 올라가고
- 큰 cluster 이면 확률이 높아짐
M-Step (Maximization Step)
-
E-Step에서 구한 확률을 이용하여 모델 파라미터 업데이트 \(\mu_\alpha = \frac{\sum_i [z_i]_\alpha x_i}{\sum_i [z_i]_\alpha}\)
- weighted 평균
-
공분산 업데이트 \(\Sigma_\alpha = \frac{\sum_i [z_i]_\alpha (x_i-\mu_\alpha)(x_i-\mu_\alpha)^T}{\sum_i [z_i]_\alpha}\)
-
mixing coefficient \(\pi_\alpha = \frac{1}{n}\sum_i [z_i]_\alpha\)
-> 확률이 높은 데이터를 더 많이 반영
장점
- Soft Assignment : 확률 기반으로 더 현실적
- Elliptical Cluster 가능 : Covariance 방향 더 퍼짐 표현
- Overlapping cluster 가능 : 겹쳐도 OK
단점
- 여전히 K 가 필요
- Gaussian 가정
- 실제 데이터는 항상 Gaussian이 아니다.
- 초기값 민감 (local optimum 문제)
Summary
- K-means vs K-medoids vs GMM
| 특징 | K-means | K-medoids | GMM |
|---|---|---|---|
| 대표값 | 평균 | 실제 데이터 | Gaussian |
| 할당 | hard | hard | soft |
| 모양 | 원형 | 거리 기반 | 타원 |
| 이상치 | 약함 | 강함 | 중간 |
| 목표 | 거리 최소화 | 거리 최소화 | likelihood 최대화 |
Density-based Clustering
왜 Density-based Clustering이 필요할까?
기존 K-Means / GMM 이 부족한 이유
- K를 미리 알아야 한다.
- K-means : 원형 클러스터 / GMM : 가우시안 분포를 가정
- 초기 Initialization 점을 어디에 두는지에 따른 결과 변화
- Outlier에 민감
DBSCAN
Density-Based Spatial Clustering of Applications with Noise
정의 : Density Connected 된 점들은 같은 클러스터
- 밀집된 곳은 하나의 클러스터
- 따로 있는 데이터는 Noise
장점 : K를 지정할 필요가 없고, 임의 모양의 클러스터도 발견이 가능하며, Outlier 처리가 좋다 (자동으로 Noise 취급)
DBSCAN 파라미터
1. Eps (ε) : 반경 (빈지름)
- 어떤 점
p가 있을 때, 반경 Eps 안에 들어오는 점들을p의 neighbor라고 함.
2. MinPts : Core Point가 되기 위해 필요한 최소 이웃 수
이웃 개수 >= MinPts: Core Point
Key Concepts of DBSCAN
1. Directly Density-Reachable 하기 위한 2가지 조건
- p가 q의 Eps-neighborhood 안에 있어야 함.
- q가 core point 여야 함.
출발점이 core point이기 때문에 Asymmetric
2. Density-Reachable
- 점 p가 q로부터 Density-Reachable하기 위해 q에서 p까지 이어지는 chain이 있어야 한다.
마찬가지로 마지막 p가 border point 이면 p에서 다시 q로 출발할 수 없기 때문에 Asymmetric
3. Density-Connected
- 점 p와 q가 Density-Connected 하려면 어떤 점 o가 존재해서,
- p가 o로부터 Density-Reachable
- q도 o로부터 Density-Reachable 이여야 한다.
- 이 관계는 Symmetric 관계이다.
키워드 정리
Core Point : Eps 안에 MinPts 이상 점이 있는 점
Border Point : 자기 주변에는 점이 충분하지 않고, 어떤 core point의 Eps안에는 있으면서 클러스터에는 포함되는 점
Noise / Outlier : core도 아니고, border도 아니고 어떤 클러스터에도 속하지 않는 점
요약 : DBSCAN에서 클러스터는 Density-Connected 된 점들의 최대 집합이다.
Process of DBSCAN : 모든 점을 한 번씩 확인하면서 클러스터를 만들어 간다.
-
시간 복잡도
- 각 점마다 다른 모든 점과 거리를 계산할 수 있다.
- 점 n개, 각 점마다 나머지 n개와 거리 계산, 거리 계산은 d차원에서 수행
Step 1. 방문하지 않은 점 하나 선택
- 아직 확인되지 않는 점 o를 하나 고르고, 이 점을 visited 로 바꾼다.
Step 2. 그 점이 core point인지 확인
- 점 o 주변 Eps 반경 MinPts 이상 점이 있으면 o는 core point
Step3 -1. Core point이면 클러스터 확장
- o로부터 Density-Reachable한 모든 점을 모아 하나의 클러스터를 만든다.
- o가 core point라면 그 이웃들을 클러스터에 넣고, 그 이웃 중 core point가 있으면 또 그 주변을 확장한다.
Step 3-2. Core point가 아니면 Temporary Noise
- 일단 nosie 로 표시
- Temporary Noise : 다른 core point의 Eps 안에 들어가서 border point가 될 수 있기 때문
Step 4. 모든 점을 방문할 때까지 반복
CLIQUE
CLustering In QUEst
(Grid-Based Clustering) 이 필요한 이유
- 고차원 데이터의 문제
- 거리가 의미가 없어진다.
- 모든 차원이 중요한 것이 아니다.
- Point-wise Density가 비싸다.
점 하나하나를 보는 대신 공간을 grid로 나누고, grid cell 단위로 밀도를 본다.
CLIQUE란?
- Grid-Based Clustering : 각 Grid 안에 점이 많으면 Dense Unit
- Subspace Clustering : 고차원에서 클러스터가 전체 공간에서는 안 보일 수 있다.
CLIQUE의 Process
Step 1. 각 차원을 Interval로 나눈다.
- 각 feature 축을 equal-width interval로 나눈다.
Step 2. Multidimensional unit 생성
- 각 차원의 Interval을 조합해서 unit을 만든다.
Step 3. Dense Unit 찾기
-
각 unit 안에 들어간 점의 개수를 센다. \(\frac{\#\text{ of points in unit}}{n} \geq \tau\)
- n : 전체 데이터 개수
Step 4. 인접한 Dense Unit 병합
- Dense Unit 들이 서로 붙어 있으면 하나의 클러스터로 합친다.
Efficient Findings of Dense Subspace
- CLIQUE도 Apriori Property를 사용
- k차원 unit이 dense 하려면, 그보다 낮은 차원의 projection들도 dense 해야 한다.
- 고차원 unit에 점이 많다는 것은 그 점들을 낮은 차원으로 projection해도 여전히 점이 많다는
Apriori Property를 활용한 Process
Step 1. Dense 1-D Unit 찾기
- 각 차원을 독립적으로 보고 dense interval을 찾는다.
- dense하지 않은 낮은 차원 unit은 버린다.
Step 2~3. Candidate k-D units 생성
- dense 한 (k-1)-D unit들을 결합해서 k-D 후보를 만든다.
Summary of CLIQUE
장점
- Scalable : 점 하나하나를 비교하지 않고 grid cell 단위로 본다.
- Different subspace에서 클러스터 찾기 가능
- Relevant Dimension 자동 식별
- Arbitrary-shaped Cluster 가능
- 인접한 dense unit 들을 병합하기 때문에 직사각형 하나가 아니라 여러 grid 가 이어진 모양도 가능
한계
- Grid size / Density Threshold에 민감
- grid를 너무 크게 잡으면 세부 구조를 놓친다.
- grid를 너무 작게 잡으면 흩어져서 dense unit이 잘 안생긴다.
- Axis-parallel Cluster 선호
- 축과 평행한 클러스터는 잘 찾지만, 대각선 방향 클러스터는 잘 못 잡을 수 있다.
- 차원이 너무 많으면 후보 subspace가 많다.
- 차원 수가 커질수록 가능한 subspace 조합이 폭발적으로 증가한다.
- Discretization 때문에 boundary point 문제
- grid 경계 근처에 있는 점은 어느 cell 에 들어가느냐에 따라 결과가 달라질 수 있다.
High-Dimensional Clustering
고차원에서 데이터에서 클러스터링이 왜 어려운가?
고차원 데이터에는 중요하지 않은 feature가 많을 수 있다.
- OverFitting의 위험 존재
- 거리계산 비용의 증가
- 설명 불가능
Curse of Dimensionality 의 문제점
- 아래 공식으로 모든 점이 비슷하게 멀어진다.
-> 해결 방법 2가지
PCA for Clustering
PCA : 차원축소
장점
- Curse of Dimensionality 완화
- Noise 제거
- Dominant Structure 유지
단점
- Not Cluster Aware : 분산만 보기에 실제로 클러스터를 구분하는 feature가 분산이 작으면 PCA가 삭제할 수도 있다.
- Negative Weight : 가중치에 음수가 들어가 Feature끼리 상쇄될 수도 있다. (Cancel out)
- Not Part-Based : 모든 Feature를 섞기에 각 성분이 무엇을 의미하는지 해석하기 어렵다.
Matrix Factorization (MF) for Clustering
latent Components : 숨겨진 요소 활용
-
raw feature 대신 latent components로 데이터를 표현한다.
-
X = n x d/X = WH
MF(Matrix Factorization)
-
거리 기반 클러스터링의 한계 : 고차원 -> 거리 측정이 불안정
- MF는 데이터를 두 개의 잠재 행렬로 분해
| 행렬 | 크기 | 의미 |
|---|---|---|
| X | n × d | 원본 데이터 |
| W | n × k | 각 데이터 포인트의 클러스터 소속 정도 |
| H | k × d | 잠재 성분(클러스터 대표 패턴) |
-
각 데이터 포인트: \(xi≈∑j=1kWi,jHj\)
- 데이터가 소수의 latent component로부터 생성된다.
Non-Negative MF
-
목적함수 \(\min ||X-WH||^2\)
- WH가 원본 X를 최대한 비슷하게 만들자
- 비음수 제약 조건 :
W, H의 모든 원소 >= 0 - 최적화 방법 :: ALS(Alternating Least Squares) 최적화
-
NMF 는 양수만 허용
- 덧셈만 사용하기에 part-based 표현으로 해석이 쉽다.
L1 Regularization (L1 정규화)
왜 L1 Regularization이 필요한가?
- W의 값들이 비슷비슷하면 어느 클러스터가 지배적인지 판단이 어렵다.
- 목적 함수
- L1 vs L2
| L1 | L2 | |
|---|---|---|
| 수식 | $|w| = w_1 + w_2 $ | $|w|^2 = w_1^2 + w_2^2 $ |
| 모양 | 마름모(diamond) | 원(circle) |
| 특징 | 뾰족한 꼭짓점 존재 | 매끄럽고 둥근 모양 |
| 효과 | 최적해가 꼭짓점으로 쏠림 → 많은 계수가 0 | 모든 계수가 0이 아닌 값으로 남음 |
| 결과 예 | $W_i = (0.01, \mathbf{0.99}) $ → sparse! | $W_i = (0.25, 0.75) $ → 분산됨 |
Spectral Graph Clustering
Motivation of Graph Clustering
핵심 질문1 : 데이터 포인트 간 연결 정보만 있다면?
- 현실 세계 문제에서는 노드의 feature 벡터가 없는 경우가 많다.
- 현실 데이터는 자연스럽게 그래프 형태로 표현
핵심 질문2 : 클러스터 구조가 비선형이라면?
- K-means & GMM : compact / spherical(구형) 클러스터를 가정
- 실제 데이터는 connected 구조가 더 적합한 경우가 있다.
- DBSCAN : Eps, MinPts에 의존 -> 밀도 변화와 스케일에 민감
- Large Eps : 두 원을 하나로 합쳐버린다.
- Small MinPts : 노이즈를 클러스터로 인식
Constructing a Similarity Graph
- 입력 데이터 X -> 유사도 그래프 W 만들기
Step 1. 쌍별 유사도 (pairwise similarity) 정의
- Cosine Similarity : 방향이 비슷할수록 유사
- Gaussian Kernel : 거리가 가까울수록 유사
Step 2. 이웃 (neighbor) 선택 후 연결
-
ε-neighborhood graph : 유사도가 임계값 ε 이상인 경우만 연결
- 수식 \(\ w_{ij} = \begin{cases} \text{similarity}, & \text{if } w_{ij} < \epsilon \\ 0, & \text{otherwise} \end{cases}\)
-
k-NN graph : 각 노드의 가장 가까운 k개 이웃만 연결
Graph Clustering
Graph Clustering ≈ Graph Partitioning
- 그래프를 서로 겹치지 않는 (disjoint) 부분 그래프들로 나누는 것
- 목표 : 내부는 강하게, 외부는 약하게
- 클러스터 내부 연결 최대화 / 클러스터 간 연결 최소화
핵심질문 3 : Where to cut?
2-Way Graph Partitioning
- 그래프
G = (V, E), 유사도 행렬WV: 노드 집합 ,E: 엣지 집합
- 목표 : 노드 집합 V를 두 개의 disjoint set A, B로 분할하여 cut을 최소화
- A, B를 가로지르는 엣지 가중치의 합 최소화
문제점 : 이 문제의 해는 trivial 하다.
- 노드 하나만 떼어내면 cut이 최소가 됨.
Normalized Cut (NCut)
- 작은 파티션에 페널티를 부여해서 균형 잡힌 분할 유도
- 분모에 노드들의 degree의 합을 부여하여 큰 파티션이 나오며 균형을 유도하도록 함.
- 최적해를 찾기는 어렵다.
- NP-hard 문제
Spectral Graph Clustering
NCut -> Spectral Relaxation 변환 과정
Step 1. 클러스터 소속 벡터 f 정의 \(f_i = \begin{cases} +1, & \text{if } i \in A \\ -1, & \text{if } i \in B \end{cases}\)
- 같은 클러스터와 다른 클러스터 정의 \((f_i - f_j)^2\)
Step 2. min cut을 f로 재표현 \(\min_f \; \mathrm{cut}(A,B) \;\rightarrow\; \min_f \frac{1}{4} \sum_{i,j} w_{ij} \left(f_i-f_j\right)^2\)
- 같은 클러스터 쌍 : 기여0 -> 무시
- 다른 클러스터 쌍 : 기여 X 4 -> 이 가중치를 최소화
Step 3. Graph Laplacian 으로 정의 \(\min_f \frac{1}{4} f^T L f\)
- Graph Laplacian :
L = D - W - Degree matrix : 대각행렬
Step 4. NCut으로 확장 \(\min_{A,B} \mathrm{Ncut}(A,B) \;\rightarrow\; \min_f \frac{f^T L f}{f^T D f}\)
- 그대로 풀어버리기엔 NP-hard
Step 5. Relaxation
-
f를 이산값 [+1, -1] 에서 연속 실수로 완화
-
이 최적화 문제의 해 -> 일반화 고유값 문제
- 결론 : f의 최적해 = L의 두 번째로 작은 고유벡터
Eigenvectors의 해석
최적 분할점을 어떻게 찾는가?
- 첫번째 고유벡터가 아닌 이유
- 첫 번째 고유값은 항상 0이고, 대응 고유벡터는 상수로 분할 정보가 없다.
| 최솟값 고유벡터 (1st) | 두 번째로 작은 고유벡터 (2nd) | |
|---|---|---|
| 값의 형태 | 모든 노드가 동일한 상수값 | 노드마다 다른 값 |
| 의미 | 모든 노드가 같은 클러스터 | 부호(sign)로 클러스터 구분 |
| 분할 가능? | No cut | Optimal cut! |
K-Partitioning
K개 클러스터로 확장하는 방법
Approach 1. Recursive Bi-partitioning
-
Spectral Clustering으로 그래프를 2개로 분할하여 한 쪽을 선택해서 다시 2개로 분할해 k개 클러스터가 될때까지 반복
-
단점 : 계산 비효율 (매 단계마다 고유분해 수행), 불안전성 (오류 수정 불가)
Approach 2. 여러 고유벡터를 새 축으로 사용
- Graph Laplacian L을 고유분해
- 상위 k개의 고유벡터 선택
- 첫 번째 trivial 벡터 제외
- 각 노드를 k차원의 새 공간으로 매핑
- 새 공간에서 k-means 등 클러스터링을 적용
- 같은 클러스터 노드들이 가깝게 모이고, 클러스터들이 선형 분리가 가능